There were quite a few teachers during my time at IIT Madras who were rumoured to have said the line “I want everyone in class to be above average”. Some people credit a professor of mathematics for saying this. At other times, the quote is ascribed to a lecturer of Engineering Drawing. In the last 20 years I’m sure even some statistics professors would have been credited with this line.
The absurdity in the line is clear. By definition, everyone cannot be above average. The average is a measure of central tendency. However you define it (arithmetic mean, geometric mean, harmonic mean, median, mode), the average is by definition a “central value”, meaning you will have numbers both above and below it. In the worst case (assuming you are using a mode or median for a highly skewed distribution), there will be a large number of data points EQUAL to the average. Everyone cannot be above (strictly greater than) average.
However, based on some recent incidents, I figured out a way in which everyone can actually be above average. All it takes is some kind of selection bias. Basically you need to be clever in terms of how you count – both when you calculate the average and when you define the “everyone”.
Take one example – you have an exam you need to pass to go from Grade 1 to Grade 2. Let’s say the class average (let’s use the simple mean here) is 41, and you need to have scored at least 40 to pass. Let’s also assume that nobody has scored exactly 40 or 41.
Now, if you come back next month and look at the exam scores of all the Grade 2 students, you will find that all of them would have scored strictly more than 41 – the old “average”. In other words, since the below average students are no longer part of the sample (since they have “not passed”), everyone left is above average! The below average set has simply been eliminated!
Another way is simple relative grading. Let’s say there are 3 sections in the class. Telling one section that “everyone should be above average” is fairly legit – all it says is that this particular section should outperform the others so significantly that everyone in this section will be above the average defined by all sections!
It is easier to do in code – using some statistical packages, as long as you slip in a few missing values into your dataset, you will find that the average is meaningless, and when you ask your software for how many are above average, the program defaults can mean that everyone can be classified as “above average” (even the ones with missing values).
I must have recommended this a few times already, but Darrell Huff’s 1954 book How to Lie With Statistics remains a masterpiece.
For a long time I have had this shibboleth on whether someone is a “statistics person or a machine learning person”. It is based on what they call regressions where the dependent variable is binary. Statisticians simply call it “logit” (there is also a “probit“).
Now, in terms of implementation as well, there is one big difference between the way “logit” is modelled versus “logistic regression”. For a logit model (if you are using python, you need to use the “statsmodels” package for this, not scikit learn), the number of observations needs to far exceed the number of independent variables.
Else, a matrix that needs to be inverted as part of the solution will turn out to be singular, and there will be no solution. I guess I betrayed my greater background in statistics than in Machine Learning when, in 2018, I wrote this blogpost on machine learning being a “process to tie down coefficients in maths models“.
For “logistic regression” (as opposed to “logit”) puts no such constraint – on the regression matrix being invertible. Instead of actually inverting the matrix, machine learning approaches simply focus on learning the terms of the inverted matrix using gradient descent (basically the opposite of hill climbing), so mathematical inconveniences such as matrices that cannot be inverted are moot there.
And so you have logistic regression models with thousands of variables, often calibrated with a fewer number of data points. To be honest, I can’t understand this fully – without sufficient information (data points) to calibrate the coefficients, there will always be a sense of randomness in the output. The model has too many degrees of freedom, and so there is additional information the model is supplying (apart from what was supplied in the training data!).
Of late I have been playing a fair bit with generative AI (primarily ChatGPT and Stable Diffusion). The other day, my daughter and I were alone in my in-laws’ house, and I told her “look I’ve brought my personal laptop along, if you want we can play with it”. And she had demanded that she “play with stable diffusion”. This is the image she got for “tiger chasing deer”.
I have written earlier here about how the likes of ChatGPT and Stable Diffusion in a way redefine “information content“.
What the likes of Dall-E and Stable Diffusion have clearly shown is that a picture is worth far less than a thousand words
And if you think about it, almost by definition, “generative AI” creates information (and hallucinates, like in the above pic). Traditionally speaking, a “picture is worth a thousand words”, but if you can generate a picture with just a few words of prompt, the information content in it is far less than a thousand words.
In some sense, this reminds me of “logistic regression” once again. By definition (because it is generative), there is insufficient “tying down of coefficients”, because of which the AI inevitably ends up “adding value of its own”, which by definition is random.
So, you will end up getting arbitrary results. ChatGPT often gives you wrong answers to questions. Dall-E and Midjourney and Stable Diffusion will return nonsense images such as the above. Because a “generative AI” needs to create information, by definition, all the coefficients of the model cannot be well calibrated.
And the consequence of this is that however good these AIs get, however much data is used to train them, there will always be an element of randomness to them. There will always be test cases where they give funny results.
The science in “data science” basically represents the “scientific method”.
It’s a decade since the phrase “data scientist” got coined, though if you go on LinkedIn, you will find people who claim to have more than two years of experience in the subject.
The origins of the phrase itself are unclear, though some sources claim that it came out of this HBR article in 2012 written by Thomas Davenport and DJ Patil (though, in 2009, Hal Varian, formerly Google’s Chief Economist had said that the “sexiest job of the 21st century” will be that of a statistician).
Some of you might recall that in 2018, I had said that “I’m not a data scientist any more“. That was mostly down to my experience working with companies in London, where I found that data science was used as a euphemism for “machine learning” – something I was incredibly uncomfortable with.
With the benefit of hindsight, it seems like I was wrong. My view on data science being a euphemism for machine learning came from interacting with small samples of people (though it could be an English quirk). As I’ve dug around over the years, it seems like the “science” in data science comes not from the maths in machine learning, but elsewhere.
One phenomenon that had always intrigued me was the number of people with PhDs, especially NOT in maths, computer science of statistics, who have made a career in data science. Initially I dismissed it down to “the gap between PhD and tenure track faculty positions in science”. However, the numbers kept growing.
The more perceptive of you might know that I run a podcast now. It is called “Data Chatter“, and is ten episodes old now. The basic aim of the podcast is for me to have some interesting conversations – and then release them for public benefit. Yeah, yeah.
So, there was this thing that intrigued me, and I have a podcast. I did what you would have expected me to do – get on a guest who went from a science background to data science. I got Dhanya, my classmate from school, to talk about how her background with a PhD in neuroscience has helped her become a better data scientist.
It is a fascinating conversation, and served its primary purpose of making me understand what the “science” in data science really is. I had gone into the conversation expecting to talk about some machine learning, and how that gets used in academia or whatever. Instead, we spoke for an hour about designing experiments, collecting data and testing hypotheses.
The science in “data science” basically represents the “scientific method“. What Dhanya told me (you should listen to the conversation) is that a PhD prepares you for thinking in the scientific method, and drills into you years of practice in it. And this is especially true of “experimental” PhDs.
And then, last night, while preparing the notes for the podcast release, I stumbled upon the original HBR article by Thomas Davenport and DJ Patil talking about “data science”. And I found that they talk about the scientific method as well. And I found that I had talked about it in my newsletter as well – only to forget it later. This is what I had written:
Reading Patil and Davenport’s article carefully suggests, however, that companies might be making a deliberate attempt at recruiting pure science PhDs for data scientist roles.
The following excerpts from the article (which possibly shaped the way many organisations think about data science) can help us understand why PhDs are sought after as data scientists.
Data scientists’ most basic, universal skill is the ability to write code. This may be less true in five years’ time (Ed: the article was published in late 2012, so we’re almost “five years later” now)
Perhaps it’s becoming clear why the word “scientist” fits this emerging role. Experimental physicists, for example, also have to design equipment, gather data, conduct multiple experiments, and communicate their results.
Some of the best and brightest data scientists are PhDs in esoteric fields like ecology and systems biology.
It’s important to keep that image of the scientist in mind—because the word “data” might easily send a search for talent down the wrong path
Patil and Davenport make it very clear that traditional “data analysts” may not make for great data scientists.
We learn, and we forget, and we re-learn. But learning is precisely what the scientific method, which underpins the “science” in data science, is all about. And it is definitely NOT about machine learning.
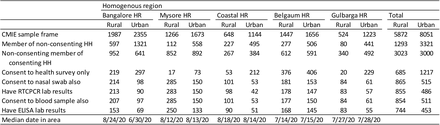
The IDFC-Duke-Chicago survey that concluded that 50% of Bangalore had covid-19 in late June only surveyed 69 people in the city.
When it comes to most things in life, the answer is 42. However, if you are trying to rationalise the IDFC-Duke-Chicago survey that found that over 50% of people in Bangalore had had covid-19 by end-June, then the answer is not 42. It is 69.
For that is the sample size that the survey used in Bangalore.
Initially I had missed this as well. However, this evening I attended half of a webinar where some of the authors of the survey spoke about the survey and the paper, and there they let the penny drop. And then I found – it’s in one small table in the paper.
The IDFC-Duke-Chicago survey only surveyed 69 people in Bangalore
The above is the table in its glorious full size. It takes effort to read the numbers. Look at the second last line. In Bangalore Urban, the ELISA results (for antibodies) were available for only 69 people.
And if you look at the appendix, you find that 52.5% of respondents in Bangalore had antibodies to covid-19 (that is 36 people). So in late June, they surveyed 69 people and found that 36 had antibodies for covid-19. That’s it.
To their credit, they didn’t highlight this result (I sort of dug through their paper to find these numbers and call the survey into question). And they mentioned in tonight’s webinar as well that their objective was to get an idea of the prevalence in the state, and not just in one particular region (even if it be as important as Bangalore).
That said, two things that they said during the webinar in defence of the paper that I thought I should point out here.
First, Anu Acharya of MapMyGenome (also a co-author of the survey) said “people have said that a lot of people we approached refused consent to be surveyed. That’s a standard of all surveying”. That’s absolutely correct. In any random survey, you will always have an implicit bias because the sort of people who will refuse to get surveyed will show a pattern.
However, in this particular case, the point to note is the extremely high number of people who refused to be surveyed – over half the households in the panel refused to be surveyed, and in a further quarter of the panel households, the identified person refused to be surveyed (despite the family giving clearance).
One of the things with covid-19 in India is that in the early days of the pandemic, anyone found having the disease would be force-hospitalised. I had said back then (not sure where) that hospitalising asymptomatic people was similar to the “precogs” in Minority Report – you confine the people because they MIGHT INFECT OTHERS.
For this reason, people didn’t want to get tested for covid-19. If you accidentally tested positive, you would be institutionalised for a week or two (and be made to pay for it, if you demanded a private hospital). Rather, unless you had clear symptoms or were ill, you were afraid of being tested for covid-19 (whether RT-PCR or antibodies, a “representative sample” won’t understand).
However, if you had already got covid-19 and “served your sentence”, you would be far less likely to be “afraid of being tested”. This, in conjunction with the rather high proportion of the panel that refused to get tested, suggests that there was a clear bias in the sample. And since the numbers for Bangalore clearly don’t make sense, it lends credence to the sampling bias.
And sample size apart, there is nothing Bangalore-specific about this bias (apart from that in some parts of the state, the survey happened after people had sort of lost their fear of testing). This further suggests that overall state numbers are also an overestimate (which fits in with my conclusion in the previous blogpost).
The other thing that was mentioned in the webinar that sort of cracked me up was the reason why the sample size was so low in Bangalore – a lockdown got announced while the survey was on, and the sampling team fled. In today’s webinar, the paper authors went off on a rant about how surveying should be classified as an “essential activity”.
In any case, none of this matters. All that matters is that 69 is the answer.
There has been a massive jump in the number of covid-19 positive cases in Karnataka over the last couple of days. Today, there were 44 new cases discovered, and yesterday there were 36. This is a big jump from the average of about 15 cases per day in the preceding 4-5 days.
The good news is that not all of this is new infection. A lot of cases that have come out today are clusters of people who have collectively tested positive. However, there is one bit from yesterday’s cases (again a bunch of clusters) that stands out.
Source: covid19india.org
I guess by now everyone knows what “travelled from Delhi” is a euphemism for. The reason they are interesting to me is that they are based on a “repeat test”. In other words, all these people had tested negative the first time they were tested, and then they were tested again yesterday and found positive.
Why did they need a repeat test? That’s because the sensitivity of the Covid-19 test is rather low. Out of every 100 infected people who take the test, only about 70 are found positive (on average) by the test. That also depends upon when the sample is taken. From the abstract of this paper:
Over the four days of infection prior to the typical time of symptom onset (day 5) the probability of a false negative test in an infected individual falls from 100% on day one (95% CI 69-100%) to 61% on day four (95% CI 18-98%), though there is considerable uncertainty in these numbers. On the day of symptom onset, the median false negative rate was 39% (95% CI 16-77%). This decreased to 26% (95% CI 18-34%) on day 8 (3 days after symptom onset), then began to rise again, from 27% (95% CI 20-34%) on day 9 to 61% (95% CI 54-67%) on day 21.
About one in three (depending upon when you draw the sample) infected people who have the disease are found by the test to be uninfected. Maybe I should state it again. If you test a covid-19 positive person for covid-19, there is almost a one-third chance that she will be found negative.
The good news (at the face of it) is that the test has “high specificity” of about 97-98% (this is from conversations I’ve had with people in the know. I’m unable to find links to corroborate this), or a false positive rate of 2-3%. That seems rather accurate, except that when the “prior probability” of having the disease is low, even this specificity is not good enough.
Let’s assume that a million Indians are covid-19 positive (the official numbers as of today are a little more than one-hundredth of that number). With one and a third billion people, that represents 0.075% of the population.
Let’s say we were to start “random testing” (as a number of commentators are advocating), and were to pull a random person off the street to test for Covid-19. The “prior” (before testing) likelihood she has Covid-19 is 0.075% (assume we don’t know anything more about her to change this assumption).
If we were to take 20000 such people, 15 of them will have the disease. The other 19985 don’t. Let’s test all 20000 of them.
Of the 15 who have the disease, the test returns “positive” for 10.5 (70% accuracy, round up to 11). Of the 19985 who don’t have the disease, the test returns “positive” for 400 of them (let’s assume a specificity of 98% (or a false positive rate of 2%), placing more faith in the test)! In other words, if there were a million Covid-19 positive people in India, and a random Indian were to take the test and test positive, the likelihood she actually has the disease is 11/411 = 2.6%.
If there were 10 million covid-19 positive people in India (no harm in supposing), then the “base rate” would be .75%. So out of our sample of 20000, 150 would have the disease. Again testing all 20000, 105 of the 150 who have the disease would test positive. 397 of the 19850 who don’t have the disease will test positive. In other words, if there were ten million Covid-19 positive people in India, and a random Indian were to take the test and test positive, the likelihood she actually has the disease is 105/(397+105) = 21%.
If there were ten million Covid-19 positive people in India, only one-fifth of the people who tested positive in a random test would actually have the disease.
Take a sip of water (ok I’m reading The Ken’s Beyond The First Order too much nowadays, it seems).
This is all standard maths stuff, and any self-respecting book or course on probability and Bayes’s Theorem will have at least a reference to AIDS or cancer testing. The story goes that this was a big deal in the 1990s when some people suggested that the AIDS test be used widely. Then, once this problem of false positives and posterior probabilities was pointed out, the strategy of only testing “high risk cases” got accepted.
And with a “low incidence” disease like covid-19, effective testing means you test people with a high prior probability. In India, that has meant testing people who travelled abroad, people who have come in contact with other known infected, healthcare workers, people who attended the Tablighi Jamaat conference in Delhi, and so on.
The advantage with testing people who already have a reasonable chance of having the disease is that once the test returns positive, you can be pretty sure they actually have the disease. It is more effective and efficient. Testing people with a “high prior probability of disease” is not discriminatory, or a “sampling bias” as some commentators alleged. It is prudent statistical practice.
Again, as I found to my own detriment with my tweetstorm on this topic the other day, people are bound to see politics and ascribe political motives to everything nowadays. In that sense, a lot of the commentary is not surprising. It’s also not surprising that when “one wing” heavily retweeted my article, “the other wing” made efforts to find holes in my argument (which, again, is textbook math).
One possibly apolitical criticism of my tweetstorm was that “the purpose of random testing is not to find out who is positive. It is to find out what proportion of the population has the disease”. The cost of this (apart from the monetary cost of actually testing) are threefold. Firstly, a large number of uninfected people will get hospitalised in covid-specific hospitals, clogging hospital capacity and increasing the chances that they get infected while in hospital.
Secondly, getting a truly random sample in this case is tricky, and possibly unethical. When you have limited testing capacity, you would be inclined (possibly morally, even) to use it on people who already have a high prior probability.
Finally, when the incidence is small, we need a really large sample to find out the true range.
Let’s say 1 in 1000 Indians have the disease (or about 1.35 million people). Using the Chi Square test of proportions, our estimate of the incidence of the disease varies significantly on how many people are tested.
If we test a 1000 people and find 1 positive, the true incidence of the disease (95% confidence interval) could be anywhere from 0.01% to 0.65%.
If we test 10000 people and find 10 positive, the true incidence of the disease could be anywhere between 0.05% and 0.2%.
Only if we test 100000 people (a truly massive random sample) and find 100 positive, then the true incidence lies between 0.08% and 0.12%, an acceptable range.
I admit that we may not be testing enough. A simple rule of thumb is that anyone with more than a 5% prior probability of having the disease needs to be tested. How we determine this prior probability is again dependent on some rules of thumb.
I’ll close by saying that we should NOT be doing random testing. That would be unethical on multiple counts.
OK, this is not a technical post. This is more in the realm of “life hacks“. It has everything to do with an observation I made a couple of months back, and how that has helped significantly combat decision fatigue.
I currently own eight pairs of shoes, which is perhaps a lifetime high. And lifetime high means that I was spending a lot of time each time I went out on which shoe to wear.
I have two pairs of open shoes, which I can’t wear for long periods of time, but are convenient in terms of time spent in wearing and taking off. I have two pairs of “semi-formal” ankle-high shoes – one an old pair that refuse to wear out, and another a rather light new one with sneaker bottoms. There are two pairs of “formal shoes”, one black and one brown. And then there are two sneakers – one pair of running shoes and one more general-purpose “fancy” one (this last one looks great with jeans, but atrocious with chinos, which I wear a lot of).
The running shoes have resided in my gym bag for the last nine months, and I use them exclusively indoors in the gym. So they’re “sorted”.
The problem I was facing was that among my seven other pairs of shoes I would frequently get confused on which one to wear. I would have to evaluate the fit with the occasion, how much I would have to stand (I need really soft-bottom shoes if I’ve to stand for a significant period of time), what trousers I was wearing and all such. It became nerve-wracking. Also, our shoe box, which was initially designed for two people and now serves three, placed its own constraints.
So as I somehow cut through the decision fatigue and managed to wear some shoes while stepping out of home, I noticed that a large proportion of the time (maybe 90%) I was wearing only three pairs of shoes. The other shoes were/are still good and I wouldn’t want to give them away, but I found that three shoes would serve the purpose on most occasions.
This is like in principal component analysis, where a small number of “components” (linear combination of variables) predict most of the variance in all the variables put together. In some analysis, you simply use these components rather than all the variables – that rather simplifies the analysis and makes it more tractable.
Since three pairs of shoes would serve me on 90% of the occasions, I decided it was time to take drastic action. I ordered a set of shoe bags from Amazon, and packed up four pairs of shoes and put them in my wardrobe inside. If I really need one of those four, it means I can put the effort at that point in time to go get that from inside. If not, it is rather easy to decide among the three outside on which one to wear (they’re rather dissimilar from each other).
I no longer face much of a decision when I’m stepping out on what shoes to wear. The shoe box has also become comfortable (thankfully the wife and daughter haven’t encroached on my space there even though I use far less space than before). Maybe sometime if I get really bored of these shoes outside, I might swap some of them with the shoes inside. But shoe life is much more peaceful now.
However, I remain crazy in some ways. I still continue to shop for shoes despite owning a lifetime high number of pairs of them. That stems from the belief that it’s best to shop for something when you don’t really need it. I’ll elaborate more on that another day.
Meanwhile I’m planning to extend this “PCA” method for other objects in the house. I’m thinking I’ll start with the daughter’s toys.
Over ten years ago, I wrote this blog post that I had termed as a “lazy post” – it was an email that I’d written to a mailing list, which I’d then copied onto the blog. It was triggered by someone on the group making an off-hand comment of “doing regression analysis”, and I had set off on a rant about why the misuse of statistics was a massive problem.
Ten years on, I find the post to be quite relevant, except that instead of “statistics”, you just need to say “machine learning” or “data science”. So this is a truly lazy post, where I piggyback on my old post, to talk about the problems with indiscriminate use of data and models.
I had written:
there is this popular view that if there is data, then one ought to do statistical analysis, and draw conclusions from that, and make decisions based on these conclusions. unfortunately, in a large number of cases, the analysis ends up being done by someone who is not very proficient with statistics and who is basically applying formulae rather than using a concept. as long as you are using statistics as concepts, and not as formulae, I think you are fine. but you get into the “ok i see a time series here. let me put regression. never mind the significance levels or stationarity or any other such blah blah but i’ll take decisions based on my regression” then you are likely to get into trouble.
The modern version of this is – everybody wants to do “big data” and “data science”. So if there is some data out there, people will want to draw insights from it. And since it is easy to apply machine learning models (thanks to open source toolkits such as the scikit-learn package in Python), people who don’t understand the models indiscriminately apply it on the data that they have got. So you have people who don’t really understand data or machine learning working with those, and creating models that are dangerous.
As long as people have idea of the models they are using, and the assumptions behind them, and the quality of data that goes into the models, we are fine. However, we are increasingly seeing cases of people using improper or biased data and applying models they don’t understand on top of them, that will have impact that affect the wider world.
So the problem is not with “artificial intelligence” or “machine learning” or “big data” or “data science” or “statistics”. It is with the people who use them incorrectly.
I’m thinking of a client problem right now, and I thought that something that we need to predict can be modelled as a function of a few other things that we will know.
Initially I was thinking about it from the machine learning perspective, and my thought process went “this can be modelled as a function of X, Y and Z. Once this is modelled, then we can use X, Y and Z to predict this going forward”.
And then a minute later I context switched into the statistical way of thinking. And now my thinking went “I think this can be modelled as a function of X, Y and Z. Let me build a quick model to see if the goodness of fit, and whether a signal actually exists”.
Now this might reflect my own biases, and my own processes for learning to do statistics and machine learning, but one important difference I find is that in statistics you are concerned about the goodness of fit, and whether there is a “signal” at all.
While in machine learning as well we look at what the predictive ability is (area under ROC curve and all that), there is a bit of delay in the process between the time we model and the time we look for the goodness of fit. What this means is that sometimes we can get a bit too certain about the models that we want to build without thinking if in the first place they make sense and there’s a signal in that.
For example, in the machine learning world, the concept of R Square is not defined for regression – the only thing that matters is how well you can predict out of sample. So while you’re building the regression (machine learning) model, you don’t have immediate feedback on what to include and what to exclude and whether there is a signal.
I must remind you that machine learning methods are typically used when we are dealing with really high dimensional data, and where the signal usually exists in the interplay between explanatory variables rather than in a single explanatory variable. Statistics, on the other hand, is used more for low dimensional problems where each variable has reasonable predictive power by itself.
It is possibly a quirk of how the two disciplines are practiced that statistics people are inherently more sceptical about the existence of signal, and machine learning guys are more certain that their model makes sense.
So I have this lecture on “smelling (statistical) bullshit” that I’ve delivered in several places, which I inevitably start with a lesson on how correlation doesn’t imply causation. I give a large number of examples of people mistaking correlation for causation, the class makes fun of everything that doesn’t apply to them, then everyone sees this wonderful XKCD cartoon and then we move on.
One of my favourite examples of correlation-causation (which I don’t normally include in my slides) has to do with religion. Praying before an exam in which one did well doesn’t necessarily imply that the prayer resulted in the good performance in the exam, I explain. So far, there has been no outward outrage at my lectures, but this does visibly make people uncomfortable.
Going off on a tangent, the time in life when I discovered to myself that I’m not religious was when I pondered over the correlation-causation issue some six or seven years back. Until then I’d had this irrational need to draw a relationship between seemingly unrelated things that had happened together once or twice, and that had given me a lot of mental stress. Looking at things from a correlation-causation perspective, however, helped clear up my mind on those things, and also made me believe that most religious activity is pointless. This was a time in life when I got immense mental peace.
Yet, for most of the world, it is not freedom from religion but religion itself that gives them mental peace. People do absurd activities only because they think these activities lead to other good things happening, thanks to a small number of occasions when these things have coincided, either in their own lives or in the lives of their ancestors or gurus.
In one of my lectures a few years back I had remarked that one reason why humans still mistake correlation for causation is religion – for if correlation did not imply causation then most of religious rituals would be rendered meaningless and that would render people’s lives meaningless. Based on what I observed today, however, I think I’ve got this causality wrong.
It’s not because of religion that people mistake correlation for causation. Instead, we’ve evolved to recognise patterns whenever we observe them, and a side effect of that is that we immediately assume causation whenever we see things happening together. Religion is just a special case of application of this correlation-causation second nature to things in real life.
So my daughter (who is two and a half) and I were standing in our balcony this evening, observing that it had rained heavily last night. Heavy rain reminded my daughter of this time when we had visited a particular aunt last week – she clearly remembered watching the heavy rain from this aunt’s window. Perhaps none of our other visits to this aunt’s house really registered in the daughter’s imagination (it’s barely two months since we returned to Bangalore, so admittedly there aren’t that many data points), so this aunt’s house is inextricably linked in her mind to rain.
And this evening because she wanted it to rain heavily again, the daughter suggested that we go visit this aunt once again. “We’ll go to Inna Ajji’s house and then it will start raining”, she kept saying. “Yes, it rained the last time it went there, but it was random. It wasn’t because we went there”, I kept saying. It wasn’t easy to explain it.
You know when you are about to have a kid you develop visions of how you’ll bring her up, and what you’ll teach her, and what she’ll say to “jack” the world. Back then I’d decided that I’d teach my yet-unborn daughter that “correlation does not imply causation” and she could use it use it against “elders” who were telling her absurd stuff.
I hadn’t imagined that mistaking correlation for causation is so fundamental to human nature that it would be a fairly difficult task to actually teach my daughter that correlation does not imply causation! Hopefully in the next one year I can convince her.
I find it incredible, and not in a good way, that I took fourteen years to make the connection between two concepts I learnt barely a year apart.
In August-September 2003, I was auditing an advanced (graduate) course on Advanced Algorithms, where we learnt about randomised algorithms (I soon stopped auditing since the maths got heavy). And one important class of randomised algorithms is what is known as “Monte Carlo Algorithms”. Not to be confused with Monte Carlo Simulations, these are randomised algorithms that give a one way result. So, using the most prominent example of such an algorithm, you can ask “is this number prime?” and the answer to that can be either “maybe” or “no”.
The randomised algorithm can never conclusively answer “yes” to the primality question. If the algorithm can find a prime factor of the number, it answers “no” (this is conclusive). Otherwise it returns “maybe”. So the way you “conclude” that a number is prime is by running the test a large number of times. Each run reduces the probability that it is a “no” (since they’re all independent evaluations of “maybe”), and when the probability of “no” is low enough, you “think” it’s a “yes”. You might like this old post of mine regarding Monte Carlo algorithms in the context of romantic relationships.
Less than a year later, in July 2004, as part of a basic course in statistics, I learnt about hypothesis testing. Now (I’m kicking myself for failing to see the similarity then), the main principle of hypothesis testing is that you can never “accept a hypothesis”. You either reject a hypothesis or “fail to reject” it. And if you fail to reject a hypothesis with a certain high probability (basically with more data, which implies more independent evaluations that don’t say “reject”), you will start thinking about “accept”.
Basically hypothesis testing is a one-sided test, where you are trying to reject a hypothesis. And not being able to reject a hypothesis doesn’t mean we necessarily accept it – there is still the chance of going wrong if we were to accept it (this is where we get into messy territory such as p-values). And this is exactly like Monte Carlo algorithms – one-sided algorithms where we can only conclusively take a decision one way.
So I was thinking of these concepts when I came across this headline in ESPNCricinfo yesterday that said “Rahul Johri not found guilty” (not linking since Cricinfo has since changed the headline). The choice, or rather ordering, of words was interesting. “Not found guilty”, it said, rather than the usual “found not guilty”.
This is again a concept of one-sided testing. An investigation can either find someone guilty or it fails to do so, and the heading in this case suggested that the latter had happened. And as a deliberate choice, it became apparent why the headline was constructed this way – later it emerged that the decision to clear Rahul Johri of sexual harassment charges was a contentious one.
In most cases, when someone is “found not guilty” following an investigation, it usually suggests that the evidence on hand was enough to say that the chance of the person being guilty was rather low. The phrase “not found guilty”, on the other hand, says that one test failed to reject the hypothesis, but it didn’t have sufficient confidence to clear the person of guilt.
So due credit to the Cricinfo copywriters, and due debit to the product managers for later changing the headline rather than putting a fresh follow-up piece.
PS: The discussion following my tweet on the topic threw up one very interesting insight – such as Scotland having had a “not proven” verdict in the past for such cases (you can trust DD for coming up with such gems).