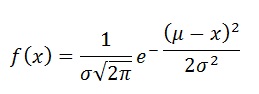All it requires is some selection bias
There were quite a few teachers during my time at IIT Madras who were rumoured to have said the line “I want everyone in class to be above average”. Some people credit a professor of mathematics for saying this. At other times, the quote is ascribed to a lecturer of Engineering Drawing. In the last 20 years I’m sure even some statistics professors would have been credited with this line.
The absurdity in the line is clear. By definition, everyone cannot be above average. The average is a measure of central tendency. However you define it (arithmetic mean, geometric mean, harmonic mean, median, mode), the average is by definition a “central value”, meaning you will have numbers both above and below it. In the worst case (assuming you are using a mode or median for a highly skewed distribution), there will be a large number of data points EQUAL to the average. Everyone cannot be above (strictly greater than) average.
However, based on some recent incidents, I figured out a way in which everyone can actually be above average. All it takes is some kind of selection bias. Basically you need to be clever in terms of how you count – both when you calculate the average and when you define the “everyone”.
Take one example – you have an exam you need to pass to go from Grade 1 to Grade 2. Let’s say the class average (let’s use the simple mean here) is 41, and you need to have scored at least 40 to pass. Let’s also assume that nobody has scored exactly 40 or 41.
Now, if you come back next month and look at the exam scores of all the Grade 2 students, you will find that all of them would have scored strictly more than 41 – the old “average”. In other words, since the below average students are no longer part of the sample (since they have “not passed”), everyone left is above average! The below average set has simply been eliminated!
Another way is simple relative grading. Let’s say there are 3 sections in the class. Telling one section that “everyone should be above average” is fairly legit – all it says is that this particular section should outperform the others so significantly that everyone in this section will be above the average defined by all sections!
It is easier to do in code – using some statistical packages, as long as you slip in a few missing values into your dataset, you will find that the average is meaningless, and when you ask your software for how many are above average, the program defaults can mean that everyone can be classified as “above average” (even the ones with missing values).
I must have recommended this a few times already, but Darrell Huff’s 1954 book How to Lie With Statistics remains a masterpiece.