Finally taking the plunge. Pertinent Observations is moving to substack.
Subscribe here:
Finally taking the plunge. Pertinent Observations is moving to substack.
Subscribe here:
I was playing with the “custom GPT” feature of ChatGPT. I asked it to build a bot to answer questions based on content in this blog. And then I started trying it out. Here is a sample:
You
NED BotYou
NED Bot
Back in 2016, footballer Oscar, then of Chelsea, was bought by Shanghai SIPT for a (then whopping) GBP 60M, with a salary of about GBP 20M a year.
Around the time the deal got announced, we were having our 10th year reunion at IIMB. During that a professor told us that one reason Shanghai had to pay Oscar so heavily was the quality (or lack thereof) of teammates he would have to deal with in Shanghai. He was then playing for Chelsea, who had won the Premier League in 2015, and would win it again that season (2016-17). And he was leaving that quality of teammates to join unknown teammates in China, and that meant he would have to be compensated heavily.
During and after last nights’ Manchester Derby, a friend and I were talking about Andre Onana, now the Manchester United goalie. Onana has been an extremely promising goalkeeper, excelling for Ajax and Inter (apart from one doping ban). He is a brilliant sweeper keeper (one reason he got chucked out of the Cameroon national team during last year’s World Cup), adept at playing with his feet and with great positioning sense.
And who does he have in front of him at ManYoo? The former Leicester defensive pair of Harry Maguire and Jonny Evans! They absolutely lack pace which means they can’t play a high line. That means Onana’s sweeping skills are grossly underutilised, and he ends up getting judged based on his shot-stopping skills, where he is nowhere in the same league as his predecessor David De Gea.
When we get into organisations, things we evaluate are the kind of work we do and what we are getting compensated for it. The thing we tend to overlook is who we need to work with, and whether they will elevate us or drag us down. Sometimes, the organisation (like Shanghai SIPT) recognises that you have to put up with suboptimal colleagues, and thus pay you a premium for your services.
Often, though, the organisation will be more like ManYoo, which doesn’t really recognise that the team around you may not be optimal for your playing style. And not everyone is willing to accept a premium in exchange for suboptimal colleagues. So, if you end up like Onana, you are not only frustrated because of the quality (or lack thereof) of your colleagues and peers, but you also end up getting judged on axes that are not your strengths (and what you have NOT been hired for).
Over the last decade, hiring at Manchester United has been curious, to say the least. There have been half-hearted attempts at changing the playing style, and almost everyone brought in to play the new style (I assume Erik Ten Haag wanted to play a more high-press style when he bought Onana) has been frustrated and unable to perform to potential.
Related to this, going back to something I’d written earlier this year, every company has an optimal rate of attrition, which is non-zero. If you end up paying too much of a premium to loyalty, you risk stagnation. If your Onana has to put up with Maguire and Evans, he won’t perform to potential. And then you go back to setting up the way it is optimal for Maguire and Evans.
The ongoing conflict between Israel and Hamas, in some ways, reminds me of my own childhood. And if I think about it, it relates to everyone’s childhoods, and to schoolboy fights in general.
A bit about myself – from early childhood I was mostly “topper types”. Yes, my school gave out “ranks” from the age of 6, and I had started topping then. This made me the teachers’ pet, and object of friends’ ire.
It didn’t help that I was the first person in class to wear spectacles, and was the slowest runner (and thus not very athletic), and had a stammer, and all this put together meant that I was an obvious target for other boys in the class to “tease” (I don’t know / remember why the girls didn’t participate in this. Maybe they had their own target).
Nowadays, I don’t have much patience for being troubled, and it was the same 35 years ago. After a little “teasing” (or bullying, if you might call it that), I would hit back. Literally. While I ran slow and was generally un-athletic, I was easily the tallest boy in the class. And so when I hit people, it hurt. On a physical 1-1 level, the fights were largely one-sided (I mostly remember whacking people, not getting whacked).
Soon this pattern emerged – someone would provoke me and in reply I would whack them. And then someone would complain to some teacher who would see that I had made a much bigger transgression than what the others had done, and then scold (or occasionally hit – my school allowed that) me, much to the joy of the others.
This kept happening, and there was seemingly no end to it. And then one day (or maybe over a period of time), ten years had gone behind us. We had grown up. We hit puberty. Our priorities in life changed. This wasn’t fun at all. We moved on. Nowadays I’m fairly good friends with many of the guys who used to tease me back then.
Thinking about it, there is nothing exclusive to me in this story. If you have siblings (I don’t), you might have seen this happen in your house. The smaller one provokes the bigger one, who hits back (mostly literally), causing a transgression much bigger than the provocation. This plays into the smaller one’s hands who then complains to the parent, who censures the bigger one, much to the joy of the smaller one. Again, this kind of stuff continues, until the kids grow up.
At some level (I know of the massive ongoing destruction and cruelty), the fight between Israel and terrorist groups such as Hamas can be thought of in a similar fashion. Israel is the “bigger kid” with an ability to whack the smaller kids to a level where they can’t hit back directly. Israel is also the kind of bigger kid who will just whack in retaliation without paying attention to “what people might think”. Hamas is like the mischievous little kid out to bug the bigger kid.
Over 75 years of fighting, the situation has now got to the point where the typical schoolboy fight gets played out, though at a much larger scale and with far far more damage. Hamas provokes Israel. Israel hits back with much greater force. It is clear that Hamas can’t whack back Israel with the same ferocity that Israel hit them. And so they go crying uncle. The “uncles” temporarily outrage. The situation (hopefully) comes back to some kind of an uneasy truce. And then it repeats.
Unfortunately, unlike schoolboys, countries (and terrorist groups) don’t grow up. I don’t know what the “puberty equivalent” for Israel and Hamas is, that will let them forget their mutual fight and unite for other common purposes. Until they find some such, the fighting will continue.
In football, normally we see two kinds of strikers – small and quick or big and slow. About twenty years ago, when 4-4-2 was the dominant formation, it was common for teams to deploy a strike partnership with one of each. Liverpool, for example, played with Michael Owen (small and quick) and Emile Heskey (bit and slow).
While strike partnerships have gone out of fashion, you still see these two kinds of strikers in modern football. The small and quick striker usually “plays on the shoulder of the last defender”, looking to beat the offside trap and score. The big and slow striker holds up the ball in an advanced position, waiting for teammates to go past, so that the team can then attack in numbers. The big and slow striker is also usually good in the air and can convert crosses.
For a long time, I was wondering why there were no “big and fast” strikers in football. It isn’t as if bulk / size is negatively correlated with speed – there surely must exist big guys who are also quick, and I was wondering why there weren’t so many strikers like this.
That, of course changed last year, with the arrival of Erling Haaland, a striker who is both incredibly quick and incredibly big, and who has dominated the Premier League like nobody’s business. Similarly, there is also Darwin Nuñez, who can both play off the last defender, and head crosses towards goal, and hold up the ball. Then again, I can’t think of too many others in contemporary football.
This morning, I got a hypothesis on why this is so – the big and fast guys are all in rugby! I was watching highlights of the quarter finals (England beating Fiji and South Africa beating France), and what I noticed was that the rugby guys are all both big and fast.
You need to be fast (and agile) to skip past the opponents to do a touchdown. And then you need tremendous upper body strength to be able to take down an opponent, or resist when an opponent tries to take you down. From that perspective, being big and being fast are both non negotiable for you to be a top rugby player.
I know there is a class difference in places like England between those who take up football and those who take up rugby (football is working class, rugby is upper class), but could it be that most people who are big and fast, and want to take up professional sport, choose rugby rather than football? And is this why you find few big and fast players from countries traditionally good at both games – such as England and France (and maybe Argentina)?
Haaland is from Norway, which doesn’t really play rugby (again, his father was a footballer). Nuñez is from Uruguay, which is a massive football nation, but not much in rugby (they made their rugby debut at this world cup, i think). And so despite their physique and speed, they chose football.
Had they been from England or France, it’s likely they would’ve played rugby instead!
Ever since I acquired this domain name (back in 2008), this blog has been hosted on WordPress. However, now I’m starting to wonder if I should port it to Substack (the URL will remain the same). Let me explain why.
Recently, the admins at Substack wrote an article that “blogging boom is back“. Quoting,
What we’re seeing now feels a lot like that early blogging boom. There was an intimacy we felt reading our favorite blogs, a personal connection to the writers and the communities that grew around them. We stacked our Google Reader with their RSS feeds and turned to them for restaurant recommendations, recipes, home decor trends, crafting inspiration, gossip, political analysis, and life advice. Writers on Substack are providing that same intimacy and connection with the communities they create. No media conglomerates edit their words and ideas. We have access to our favorite writers, just as we did in those fast blogging days. We see ourselves in the personal stories they share; we trust them.
Having started (and not really continued) some five or six substacks in the last five years, I broadly agree to this sentiment. And the reason why I feel like Substack might be “the old blogging in a new form” is due to comments. People actually comment on Substack, unlike on WordPress.
I was reading a friend’s substack yesterday, and noticed a possibly Freudian slip. I quickly hit the comment button and shot off a comment. As of this morning, he has already seen it and replied. This was a regular feature on the blogosphere in the late 2000s. In the 2010s, this kind of behaviour simply died.
And coming to think of it, it possibly has to do with user experience. The user experience for commenting on WordPress absolutely sucks. There is no concept of login across sites (I don’t know when this “openID” was last maintained). So every time you need to write a comment, you need to enter your name, email, website, and maybe even fill a captcha before your comment gets accepted. And that is IF your comment gets accepted (the number of times I’ve written an elaborate comment and seen it NOT go through is insane).
Two decades ago, when blogging was big and growing rapidly, people used to leave comments on one another’s blogs. A LOT. In fact, I discovered a lot of blogs I followed back in the day by following comment trails from blogs that I already liked. It could occasionally be riotous, like on this legendary post by Ravikiran Rao.
And then sometime in 2010 or 11, it all stopped. Almost all of a sudden. I have statistics on number of comments per post on this blog over the years, but right now NED to pull it up (and also, the commenting was heavier when this site was on LJ). Suddenly people stopped commenting. And I think this had an impact on blogging as well. With little or no feedback, people didn’t feel like writing.
People started talking about the death of blogs. Sometimes, writing this would feel like shouting into an empty room. Then again, I’ve considered this as a documentation of my life and my thoughts (and your benefits, if any, being strictly collateral), and carried on.
What Substack seems to have shown is that the appetite for blogging didn’t go away. The appetite for commenting also didn’t go away. It’s only the user experience. Over the years, maybe coinciding with WordPress being the dominant blogging platform (and WordPress being more popular for making websites than for blogs), the user experience of commenting deteriorated. And as people commented less, they blogged less.
Now, looking at the comment density on Substack, I’m seriously considering if I should make a shift there. Still need to see how easily I can port all of this stuff without breaking. But if I can, I might just. What do you think? Do leave a comment (and if you think this blogpost is too hard to comment on, maybe comment on this “note” instead).
Sometimes we overdo “option value”. We do things that have a small possibility of a big upside, and big possibility of no or very minimal downside, in the belief that “nothing can go wrong in trying”.
My father used to term this “pulling a mountain with a string”, with the reasoning being that if you actually manage to pull, then you have moved a mountain. If not, all that you have lost is a string.
There is one kind of situation, however, where I think we might overindex on option value – these are what I call “one shot events” or “brahmastras”.
Going into a little bit of mythology, there is the story of the Brahmastra in the Mahabharata. Famously, Karna possesses it. It is an incredibly powerful weapon with the feature (or bug, rather) that it can be used only once. Karna would have set it aside to use on Arjuna, but the Pandavas decide to send Ghatotkacha to create havoc during the night fight when Karna is forced to use up his brahmastra on Ghatotkacha – meaning he didn’t have access to it in his battle with Arjuna, where he (Karna) ultimately got killed.
Because the Brahmastra could be used only once, Karna wanted to maximise the impact of the weapon. His initial plan was to use it on what he thought might be a decisive battle with Arjuna. The Pandavas’ counterplan was to force him to use it earlier.
Actually, thinking about it – the Brahmastra can be thought of as another kind of option. The problem here being one of optimal exercise. Actually, there is a very stud paper written by economist Avinash Dixit on this topic – regarding Elaine’s sponges.
Read the whole paper. It is surely worth it. To quickly summarise, Elaine has a limited number of “contraceptive sponges”, and wants to maximise her “utility” of using them. When a guy comes along, she needs to decide whether it is worth expending a sponge on him. Dixit derives a nice equation to determine a function for this.
Basically, Brahmastra occurs when you have only one sponge left, and you need to use it at an “optimal time”. There is another problem in economics called the “secretary problem” (nothing to do with secretary birds) that deals with this.
Recently I’ve been thinking – these kind of Brahmastra / sponge / secretary problems are important to solve when you are thinking of talking to someone.
Let’s say you have what you think is a studmax application of GenAI and want to talk to VCs about it. If you go too early, the VC will only see a half-baked version of your idea, and even if you go to them later once you have fully formed it, the half-baked idea you had showed them will influence them enough to discount your later fully formed idea.
And if you go too late, the idea may not be that studmax any more, and the VC might dismiss it. So it’s a problem of “optimal exercise” (note that this is an issue only with American options, not European).
It is similar with asking someone out (or so I think – I’ve been out of this business for 14 years now). You approach them “too early” (before they know you), they will dismiss you then and then forever. You approach too late and the option would have expired.
In the world of finance, we focus too much on the PRICE of options and (based on my now limited knowledge) too little on optimal expiry of the said options. In the real world, the latter is also important.
A month or two ago, my wife wrote this studmax blogpost about “Mid Life Crises“. I read it when I was in draft. I read it again soon after it was published. And I read it again, and again, and again. And I’ve been showing it to a lot of people I meet.
Having seen this post, it has been impossible to unsee. I used to wonder why Hospi puts so many dance videos on Instagram, and then realised it must be mid-life crisis. I saw Josh go from being a VLSI Engineer to pushing limits, and have classified that as mid-life crisis as well. Recently, Ruddra posted topless gym photos. I actually commented that it “must be mid life crisis”.
A few days ago, my wife and I were talking about an acquaintance who is possibly having an affair, and that again we put down to “mid life crisis”. When asked why he had had a second child eight years after his first, a relative had said “early forties you hit mid life crisis. We had the option of a sports car or another kid. Decided to go for the latter”.
You see – once you’ve seen this concept, and if you belong to the broad 35-50 age group, it is absolutely impossible to un-see. You get excited about possibly meeting an old flame after ages, and mid-life crisis explains that. You want to get hammered when you meet your old friends, and mid-life crisis explains that as well.
Now, being 40 and having identified that I’m at “mid life”, the challenge is to deal with the crisis in the least destructive manner possible. That the crisis exists, and needs to be dealt with, is a fact. The choice is in terms of how to deal with it.
If you are married (or in a long term relationship), you don’t want to have an affair and put that in jeopardy (also the question needs to be asked if one’s demand for an affair can be met with supply). Alcohol and dope can be destructive to your physical and mental health. Social media gives you dopamine (and I think that was my main tool of dealing with mid-life crisis till recently), but can be both addictive and anxiety-causing. Gaming (I’ve considered buying a console for nearly 2 years now, but I’m yet to act on it) gives you the dopamine but again comes with addiction risk.
And that is where the “healthy obsessions come in”. You notice that many people around my age take to running, or cycling, or lifting, or a combination of these. All of these are physically strenuous activities, and thus can give you your endorphins. As an added bonus, they increase either your cardiovascular health or your muscle strength, thus preparing you better for old age.
So you find these to be fairly common midlife-dealing hobbies. If you can find one of these that you don’t get bored by, it’s a clear win-win (I lift weights). The “problem” is that because it is physically strenuous you can only do so much of it (I go to the gym for an hour each 2-3 times a week. If you do less strenuous stuff like running, you can perhaps do an hour 7 times a week). And so you need more. The question is what you can choose that is non-destructive (relatively speaking).
A month or two back, I got introduced to online quizzing. I’m currently playing three leagues (one of them will end soon, but I’ve signed up for yet another starting at the end of this month). I find that this is a fairly high-dopamine hobby (to the extent that now I’ve started doing this late in the night since it interferes with my sleep), and keeps me stimulated enough. The only issue is it can be potentially addictive (when I played my first “friendly” online quiz 2-3 weekends ago, I felt the same way as I did when I smoked my first cigarette – “this is addictive shit, I need to be careful”).
Interestingly, two friends I spoke to in the week of August 15th (and I’m pretty sure those two have never met or spoken to each other) told me “start working on another book to deal with your mid life crisis”. I admit they too have a point, but I don’t know what to write about.
But yes – midlife crisis is a real thing. It is only about how you choose to deal with it without causing self-harm.
A few months back, at work, a couple of kids in my team taught me this concept called “SHAP“. I won’t go into the technical details here (or maybe I will later on in this post), but it is basically an algo that helps us explain a machine learning model.
It was one of those concepts that I found absolutely mind-blowing, to the extent that after these guys taught this concept to me, it became the proverbial hammer, and I started looking for “nails” all around the company. I’m pretty sure I’ve abused it (SHAP I mean).
Most of the documentation of SHAP is not very good, as you might expect about something that is very deeply technical. So maybe I’ll give a brief intro here. Or maybe not – it’s been a few months since I started using and abusing it, and so I’ve forgotten the maths.
In any case, this is one of those concepts that made me incredibly happy on the day I learnt about it. Basically, to put it “in brief”, what you essentially do is to zero out an explanatory variable, and see what the model predicts with the rest of the variables. The difference between this and the actual model output, approximately speaking, is the contribution of this explanatory variable to this particular prediction.
The beauty of SHAP is that you can calculate the value for hundreds of explanatory variables and millions of observations in fairly quick time. And that’s what’s led me to use and abuse it.
In any case, I was reading something about American sport recently, and I realised that SHAP is almost exactly identical (in concept, though not in maths) to Wins Above Replacement.
WAR works the same way – a player is replaced by a hypothetical “average similar player” (the replacement), and the model calculates how much the team would have won in that case. A player’s WAR is thus the difference between the “actuals” (what the team has actually won) and the hypothetical if this particular player had been replaced by the average replacement.
This, if you think about it, is exactly similar to zeroing out the idiosyncrasies of a particular player. So – let’s say you had a machine learning model where you had to predict wins based on certain sets of features of each player (think of the features they put on those otherwise horrible spider charts when comparing footballers).

You build this model. And then to find out the contribution of a particular player, you get rid of all of this person’s features (or replace it with “average” for all data points). And then look at the prediction and how different it is from the “actual prediction”. Depending on how you look at it, it can either be SHAP or WAR.
In other words, the two concepts are pretty much exactly the same!
A few months back, I came across this article that talked about margins in the software industry. Long ago, computer software was well known to be an insanely high gross margin industry. However, it is not the case any more.
If you look at SaaS (software as a service) companies, a lot of them barely make much profits any more. So what changed?
The answer is infrastructure. In the olden days, when all hardware was “on premise”, software would be a bunch of lines of code that would get sold, and then run on the client’s on-premise hardware. Thus, once the code had been written and tested and perfected, the only cost that the vendor faced was to install the code on the client’s hardware (including the cost of engineers involved in the installation). And the margins soared.
Then (I’m still paraphrasing the article that I had read, and now can’t find), the cloud happened. Hardware wasn’t all on-premise any more. People figured out that software could be sold “as a service” (hence SaaS). Which means, instead of charging for installing some code on a computer, you could charge for API hits, or function calls. Everything became smooth.
The catch, though, was that the software would now have to be hosted on hardware maintained (in the cloud) by the vendor. Which meant now the marginal cost of delivery suddenly became non-zero. Rather, it went from 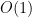

I’m thinking of this now in the wake of new-fangled open source LLMs that keep getting announced every day. Every new LLM that comes out gets compared with ChatGPT, and people tell you that this new LLM is “open source”. And you get excited that you can get for free what you would have to pay for with ChatGPT.
Of course, the catch here is that ChatGPT is like SaaS – not only does it provide you the “LLM service” it also hosts the service for you and answers your questions, for a fee.
These open source models are like the traditional “on-premise” computer software industry – they have good code but the issue of course is that you need to supply your own hardware. Add in the cost of maintaining the said hardware, and you see where you might spend with the open source LLMs.
That said, Free != Open Source. The Open Source LLMs are not only free, but also open source – and so, the real value in them is that you can actually build on the existing algorithms and not have to pay a fee (except for your own infrastructure).
And from that perspective, it’s exciting that so many new tools are coming along.