Rob Henderson writes that in general, relative to the value they add to their firms, senior employees are underpaid and junior employees are overpaid. This, he reasons, is because senior employees trade off money for status.
Quoting him in full:
Robert Frank suggests the reason for this is that workers would generally prefer to occupy higher-ranked positions in their work groups than lower-ranked ones. They’re forgoing more earnings to hold a higher-status position in their organization.
But this preference for a higher-status position can be satisfied within any given organization.
After all, 50 percent of the positions in any firm must always be in the bottom half.
So the only way some workers can enjoy the pleasure inherent in positions of high status is if others are willing to bear the dissatisfactions associated with low status.
The solution, then, is to pay the low-status workers a bit more than they are worth to get them to stay. The high-status workers, in contrast, accept lower pay for the benefit of their lofty positions.
I’m not sure I agree. Yes, I do agree that higher productivity employees are underpaid and lower productivity employees are overpaid. However, I don’t think status fully explains it. There are also issues of variance and correlation and liquidity (there – I’m talking like a real quant now).
One the variance front – the higher you are in the organisation and the higher your salary is, the more the variance of your contribution to the organisation. For example, if you are being paid $350,000 (the number Henderson hypothetically uses), the actual value you are bringing to your firm might have a mean of $500,000 and a standard deviation of $200,000 (pulling all these numbers out of thin air, while making some sense checks that broadly risk pricing holds).
On the other hand, if you are being paid $35,000, then it is far more likely that the average value you bring to the firm is $40,000 with a standard deviation of $5,000 (again numbers entirely pulled out of thin air). Notice the drastic difference in the coefficient of variation in the two cases.
Putting it another way, the more productive you are, the harder it is for any organisation to put a precise value on your contribution. Henderson might say “you are worth 500K while you earn 350K” but the former is an average number. It is because of the high variance in your “worth” that you are paid far lower than what you are worth on average.
And why does this variance exist? It’s due to correlation.
More so at higher ranked positions (as an aside – my weird career path means that I’ve NEVER been in middle management) the value you can add to a company is tightly coupled with your interactions with your colleagues and peers. As a junior employee your role can be defined well enough that your contributions are stable irrespective of how you work with the others. At senior levels though a very large part of the value you can add is tied to how you work with others and leverage their work in your contributions.
So one way a company can get you to contribute more is to have a good set of peers you like working with, which increases your average contribution to the firm. Rather paradoxically, because you like your peers (assuming peer liking in senior management is two way), the company can get away with paying you a little less than your average worth and you will continue to stick on. If you don’t like working with your colleagues, there is the double whammy that you will add less to the company and you need to be paid more to stick on. And so if you look at people who are actually successful in their jobs at a senior level, they will all appear to be underpaid relative to their peers.
And finally there is liquidity (can I ever theorise about something without bringing this up?). The more senior you go, the less liquid is the market for your job. The number of potential jobs that you want to do, and which might want you, is very very low. And as I’ve explained in the first chapter of my book, when a market is illiquid, the bid-ask spread can be rather high. This means that even holding the value of your contribution to a company constant, there can be a large variation in what you are actually paid. And that is a gain why, on average, senior employees are underpaid.
So yes, there is an element of status. But there are also considerations of variance, correlation and bid-ask. And selection bias (senior employees who are overpaid relative to the value they add don’t last very long in their jobs). And this is why, on average, you can afford to underpay senior employees.



 , the average returns or the drift, is defined as “returns per unit time”. So a stock that returns, on average, 10% in a year returns 20% in two years. So returns has dimensions
, the average returns or the drift, is defined as “returns per unit time”. So a stock that returns, on average, 10% in a year returns 20% in two years. So returns has dimensions 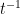 , and multiplying it with
, and multiplying it with 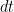 which has the unit of time renders it dimensionless.
which has the unit of time renders it dimensionless.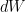 is the Wiener Process, and is defined such that
is the Wiener Process, and is defined such that 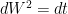 . This implies that
. This implies that 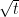 . This means that the equation is meaningful if and only if
. This means that the equation is meaningful if and only if  has dimensions
has dimensions 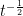 , which is the same as saying that
, which is the same as saying that 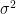 has dimensions
has dimensions  , which is the same as the dimensions of the mean returns.
, which is the same as the dimensions of the mean returns.