I first learnt about the concept of Standard Deviation sometime in 1999, when we were being taught introductory statistics in class 12. It was classified under the topic of “measures of dispersion”, and after having learnt the concepts of “mean deviation from median” (and learning that “mean deviation from mean” is identically zero) and “mean absolute deviation”, the teacher slipped in the concept of the standard deviation.
I remember being taught the mnemonic of “railway mail service” to remember that the standard deviation was “root mean square” (RMS! get it?). Calculating the standard deviation was simple. You took the difference between each data point and the average, and then it was “root mean square” – you squared the numbers, took the arithmetic mean and then square root.
Back then, nobody bothered to tell us why the standard deviation was significant. Later in engineering, someone (wrongly) told us that you square the deviations so that you can account for negative numbers (if that were true, the MAD would be equally serviceable). A few years later, learning statistics at business school, we were told (rightly this time) that the standard deviation was significant because it doubly penalized outliers. A few days later, we learnt hypothesis testing, which used the bell curve. “Two standard deviations includes 95% of the data”, we learnt, and blindly applied to all data sets – problems we encountered in examinations only dealt with data sets that were actually normally distributed. It was much later that we figured that the number six in “six sigma” was literally pulled out of thin air, as a dedication to Sigma Six, a precursor of Pink Floyd.
Somewhere along the way, we learnt that the specialty of the normal distribution is that it can be uniquely described by mean and standard deviation. One look at the formula for its PDF tells you why it is so:
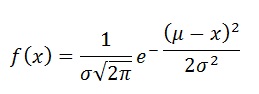
Most introductory stats lessons are taught from the point of view of using stats to do science. In the natural world, and in science, a lot of things are normally distributed (hence it is the “normal” distribution). Thus, learning statistics using the normal distribution as a framework is helpful if you seek to use it to do science. The problem arises, however, if you assume that everything is normally distributed, as a lot of people do when they learn deep statistics using the normal distribution.
When you step outside the realms of natural science, however, you are in trouble if you were to blindly use the standard deviation, and consequently, the normal distribution. For in such realms, the normal distribution is seldom normal. Take, for example, stock markets. Most popular financial models assume that the movement of the stock price is either normal or log-normal (the famous Black-Scholes equation uses the latter assumption). In certain regimes, they might be reasonable assumptions, but pretty much anyone who has reasonably followed the markets knows that stock price movements have “fat tails”, and thus the lognormal assumption is not a great example.
At least the stock price movement looks somewhat normal (apart from the fat tails). What if you are doing some social science research and are looking at, for example, data on people’s incomes? Do you think it makes sense at all to define standard deviation for income of a sample of people? Going further, do you think it makes sense at all to compare the dispersion in incomes across two populations by measuring the standard deviations of incomes in each?
I was once talking to an organization which was trying to measure and influence salesperson efficiency. In order to do this, again, they were looking at mean and standard deviation. Given that the sales of one salesperson can be an order of magnitude greater than that of another (given the nature of their product), this made absolutely no sense!
The problem with the emphasis on standard deviation in our education means that most people know one way to measure dispersion. When you know one method to measure something, you are likely to apply it irrespective of whether it is the appropriate method to use given the circumstances. It leads to the proverbial hammer-nail problem.
What we need to understand is that the standard deviation makes sense only for some kinds of data. Yes, it is mathematically defined for any set of numbers, but it makes physical sense only when the data is approximately normally distributed. When data doesn’t fit such a distribution (and more often than not it doesn’t), the standard deviation makes little sense!
For those that noticed, the title of this post is a dedication to Tyler Cowen’s recent book.