Regular readers of this blog will know very well that I keep talking about how everything in life is Bayesian. I may not have said it in those many words, but I keep alluding to it.
For example, when I’m hiring, I find the process to be Bayesian – the CV and the cover letter set a prior (it’s really a distribution, not a point estimate). Then each round of interview (or assignment) gives additional data that UPDATES the prior distribution. The distribution moves around with each round (when there is sufficient mass below a certain cutoff there are no more rounds), until there is enough confidence that the candidate will do well.
In hiring, Bayes theorem can also work against the candidate. Like I remember interviewing this guy with an insanely spectacular CV, so most of the prior mass was to the “right” of the distribution. And then when he got a very basic question so badly wrong, the updation in the distribution was swift and I immediately cut him.
On another note, I’ve argued here about how stereotypes are useful – purely as a Bayesian prior when you have no more information about a person. So you use the limited data you have about them (age, gender, sex, sexuality, colour of skin, colour of hair, education and all that), and the best judgment you can make at that point is by USING this information rather than ignoring it. In other words, you need to stereotype.
However, the moment you get more information, you ought to very quickly update your prior (in other words, the ‘stereotype prior’ needs to be a very wide distribution, irrespective of where it is centred). Else it will be a bad judgment on your part.
In any case, coming to the point of this post, I find that the respect I have for people is also heavily Bayesian (I might have alluded to this while talking about interviewing). Typically, in case of most people, I start with a very high degree of respect. It is actually a fairly narrowly distributed Bayesian prior.
And then as I get more and more information about them, I update this prior. The high starting position means that if they do something spectacular, it moves up only by a little. If they do something spectacularly bad, though, the distribution moves way left.
So I’ve noticed that when there is a fall, the fall is swift. This is again because of the way the maths works – you might have a very small probability of someone being “bad” (left tail). And then when they do something spectacularly bad (well into that tail), there is no option but to update the distribution such that a lot of the mass is now in this tail.
Once that has happened, unless they do several spectacular things, it can become irredeemable. Each time they do something slightly bad, it confirms your prior that they are “bad” (on whatever dimension), and the distribution narrows there. And they become more and more irredeemable.
It’s like “you cannot unsee” the event that took their probability distribution and moved it way left. Soon, the end is near.




 ), , 3 (
), , 3 ( ) and 2 (
) and 2 ( ) camels respectively. One camel was left over – the neighbour’s, who took it back.
) camels respectively. One camel was left over – the neighbour’s, who took it back.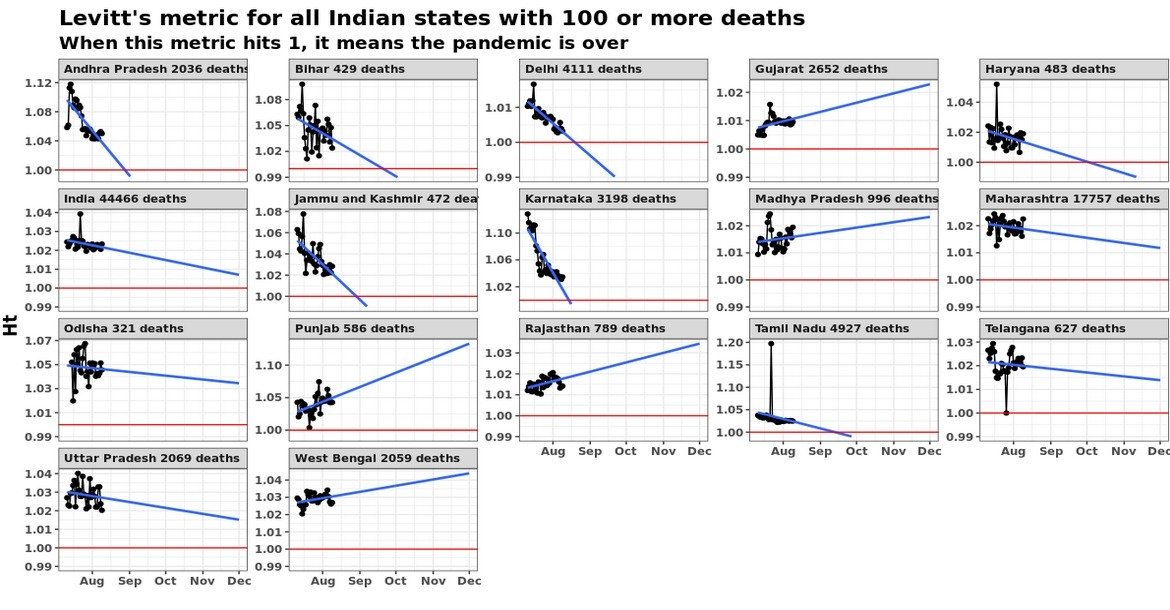


 where
where  is the standard deviation of the underlying distribution. And when the underlying distribution itself is a power law distribution with an exponent less than 2 (as the case is in India),
is the standard deviation of the underlying distribution. And when the underlying distribution itself is a power law distribution with an exponent less than 2 (as the case is in India),