On Saturday morning, my daughter had made some nice art with sketch pen on an A4 paper. It was rather “geometric” consisting of repeating patterns across the page. My wife took one look at it and said, “do you know that you can make such art with computers also? Your father has made some”.

“Reallly?”, piped the daughter. I had been intending for a while to start teaching her to code (she is six), and figured this was the perfect trigger, and said I will teach her.
A quick search revealed that there is an “ACS Logo” for Mac (Logo was the first “programming language” I had learnt, when I was nine). I quickly downloaded it on her computer (my wife’s old Macbook Air) and figured I remembered most of the commands.
And then I started typing, and showed her what they had showed me back in a “computer class” behind my house in 1992 – FD for “forward”. RT for right turn. HT for hide turtle. Etc. Etc.
Soon she was engrossed in it. Thankfully she has learnt angles in her school, though it took her some trial and error to figure out how much to turn by for different shapes (later I was thinking this can also serve as a good “angles revision” for her during her ongoing summer holidays).
With my wife having reminded me that I could produce images through code, I realised that as my daughter was engrossed in her “coding”, I should do some “coding art” on my own. All she needed was some occasional input, and for me to sit right next to her.
Last Monday I had got a bit of a scare – at work, I needed to generate randomly distributed points in a regular hexagon. A lookup online told me that I could just get a larger number of randomly distributed points in a bounding rectangle, and then only pick points within the hexagon. And then take a random sample of those.
This had meant that I needed to write equations for whether a point lay inside a hexagon. And I realised I’d forgotten ALL my coordinate geometry. It took me over half an hour to get the equation for the sides of the hexagon right – I’m clearly rusty.
And on Saturday, as I sat down to make some “computer art”, I decided I’ll make some fractals. Why don’t I make some Sierpinski Triangles, I thought. I started breaking down what code I needed to write.
First, given an equilateral triangle, I had to return three similar equilateral triangles, each of half the side length of the original triangles.
Then, given the centroid of an equilateral triangle and the length of each side, I had to return the vertices.
Once these two functions had been written, I could just chain them (after running the first one recursively) and then had to just plot to get the Sierpinski triangle.
And then I had my second scare of the week – not only had I forgotten my coordinate geometry – I had forgotten my trigonometry as well. Again I messed up a few times, but the good thing about programming with a computer is that i could do trial and error. Soon I had it right, and started producing Sierpinski triangles.
Then, there was another problem – my code was really inefficient. If I went beyond depth 4 or 5, the figures would take inordinately long to render. Since I was coding in R, I set about vectorising all my code. In R you don’t write loops if you can help it – instead, you apply functions on entire vectors. This again took some time, and then I had the triangles ready. I proudly showed them off to my daughter.
“Appa, why is it that as you increase the number it becomes greyer”, she asked . I explained how with each step, you were taking away more of the filled areas from the triangles. Then I figured this wasn’t that good-looking – maybe I should colour it.
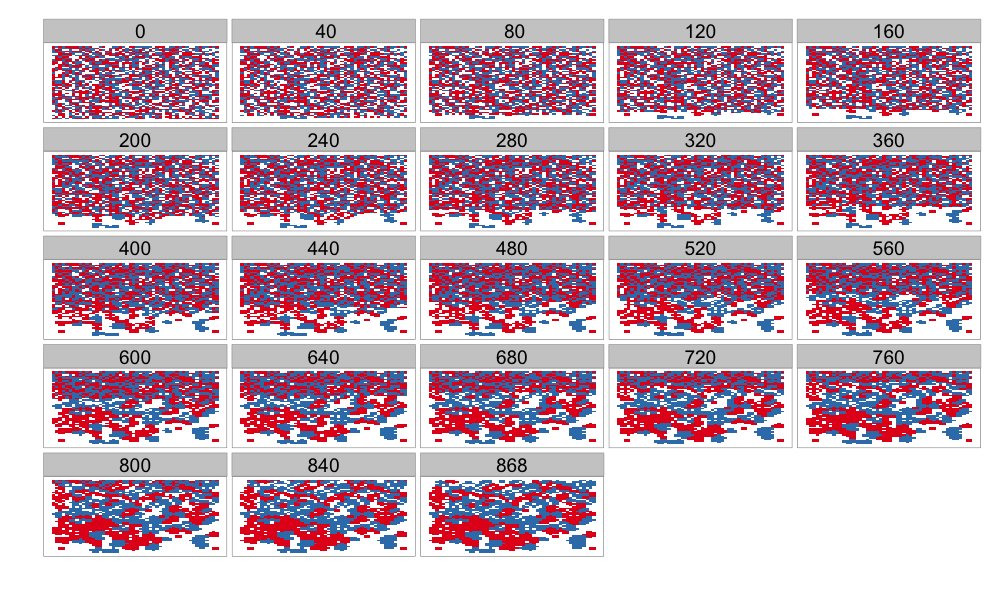
And so I wrote code to colour the triangles. Basically, I started recursively colouring them – the top third green, left third red and right third blue (starting with a red base). This is what I ended up producing:

And this is what my daughter produced at the same time, using Logo: