One of my favourite concepts in Computer Science is Shannon’s Channel Coding Theorem. This theorem is basically about the efficiency of communication over a noisy channel. And as I was thinking a few minutes back, this has interesting implications in real life as well, well away from the theory of communication.
I don’t have that much understanding of the rigorous explanation of the theorem. However, I absolutely love the central idea of it – that the noisier a channel is, the more the redundancy you need in your communication, and thus the slower is your communication. A corollary of this is that every channel has a “natural maximum speed”, and as long as you try to communicate within that speed, you can communicate reliably.
I won’t go into the technical details here – that involves assuming that the channel loses (or garbles) X% of bits, and then constructing a redundant code that shows that even with this loss, you can communicate effectively.
Anyway, let’s leave behind the theory communication and go on to real life.
I’ve found that I communicate badly when I’m not sure what language to talk in. If I’m talking in English with someone who I know knows good English, I communicate rather well (like my writing 😛 ) . However, if I’m not sure about the quality of language of the other person, I hesitate. I try to force myself to find simpler / more obvious words, and that disturbs my flow of thought, and I stammer.
Similarly, when I’m not sure whether to talk in Kannada or English (the two languages I’m very comfortable in), I stammer heavily. Again, because I’m not sure if the words I would naturally use will be understood by the other person (the counterparty’s comprehension being the “noise in the channel” here), I slow down, get jittery, and speak badly.
Then of course, there is the very literal interpretation of the channel coding theorem – when your internet connection (or call quality in general) is bad, you end up having to speak slower. When I was hunting for a job in 2020, I remember doing badly in a few interviews because of the quality (or lack thereof) of the internet connection (this was before I had discovered that Google Meet performs badly on Safari).
Similarly, sometime last month, I had thought I had prepared well for what I thought was going to be a key conversation at work. The internet was bad, we couldn’t hear each other and kept repeating (redundancy is how you overcome the noise in the channel), and that diminished throughput massively. Given the added difficulty in communication, I didn’t bring up the key points I had prepared for. It was a damp squib.
Related to this is when you aren’t sure if the person you are speaking to can hear clearly. This disability again clouds the communication channel, meaning you need to build in redundancy, and thus a reduction in throughput.
When you are uncertain of yourself, or underconfident, you end up tending to do badly. That is because when you are uncertain, you aren’t sure if the other person will fully understand what you are going to say. Consequently, you end up talking slower, building redundancy in your speech, etc. You are more doubtful of what you are going to say, and don’t take risks, since your lack of confidence has clouded the “communication channel”, thus depressing your throughput.
Again a lot of this might apply to me alone – I function best when I’m talking / writing at a certain minimum throughput, and operating at anywhere below that makes me jittery and underconfident and a bad communicator. It is no surprise that my writing really took off once I got a computer of my own.
That was in the beginning of July 2004, and within a month, I had started (the predecessor of) this blog. I’ve been blogging for 19 years now.

That aside aside, the channel coding theorem works in non-verbal contexts as well. Back in 2016, before my daughter was born, I remember reading somewhere that tentative mothers lead to cranky babies. The theory was that if the mum was anxious or afraid while handling her baby, the baby wouldn’t perceive the signals of touch sufficiently, and being devoid of communication, become cranky.
We had seen a few examples of this among relatives and friends (and this possibly applies to me as well – my mother had told me that I was the first newborn she ever handled, and so she was a bit tentative in handling me). This again can be explained using the Channel Coding Theorem.
When the mother’s touch is tentative, it is as if the touchy channel between mother and child has some “noise”. The tentativeness of the touch means the baby is not really sure of what the mother is “saying”. With touch, unlike language or bits, redundancy is harder. And so the child goes up insufficiently connected to its mother.
Conversely, later on in life, these tentative mothers tend to bring in redundancy in their communications with their (now jittery) children, and end up holding them too hard, and not letting them go (and some of these children go to therapists, who inevitably blame it on the mothers 😛 ). Ultimately, all of this stems from the noise in the initial communication channel (thanks to the tentativeness of the source).
Ok I’ve rambled on here, so will stop now. However, now that I’ve seeded this thought in you, you too will start seeing the channel coding theorem everywhere (oh – if you think this post is badly written, then that is again like reading this over a noisy channel. And you will get irritated with the lack of throughput and pack).


 “, I realised in my head, and decided this is a good time to teach my daughter binary search.
“, I realised in my head, and decided this is a good time to teach my daughter binary search. “? And went on to “is the number
“? And went on to “is the number  “, and got to the number in my wife’s mind (74) in exactly 7 guesses (and you might guess that
“, and got to the number in my wife’s mind (74) in exactly 7 guesses (and you might guess that  (90 is the number of 2 digit numbers) is 7).
(90 is the number of 2 digit numbers) is 7).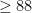 ?”
?”