Some of you might know that I do this daily covid-19 update on twitter (not linking since I delete each day’s posts the next morning). A couple of weeks back I revamped it, in advance of which I asked what people wanted to see.
A lot of people suggested I use “Levitt’s metric”. I ignored it. Then, after I had revamped the output last week, two people I know very well got in touch asking me to report that metric every morning in my update. This time I decided to do it, and added it to my update on Monday.
My daily update has the smoothed line using a loess smoothing, but I also wanted to see if I can “predict” when the pandemic might end in different places. And so I did a linear fit as well (using 1 month of data – the slope of the line is highly sensitive to how far back you go), and posted it on Twitter.
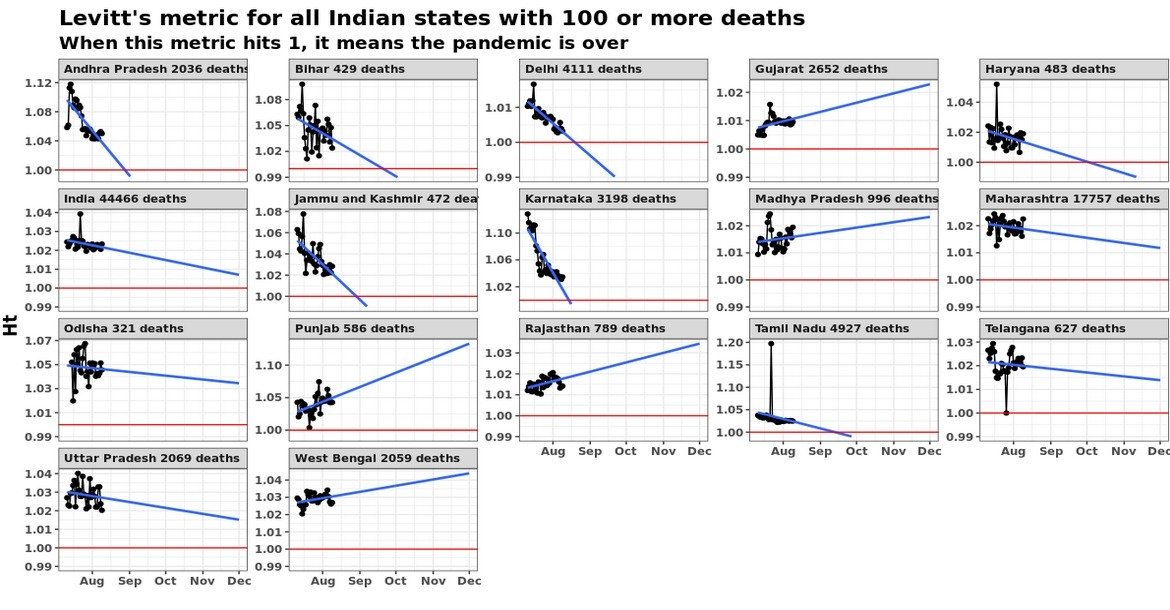
I’ve extended the X axis of the graph until the end of the year. The idea is that when the blue line (the regression line based on the last 30 data points) hits the red line, the pandemic in that place is “effectively over”. So we can predict when the pandemic might end in different places.
Now, if you slightly contort your neck and try and extend the “india” graph here rightwards, you might see that the pandemic might end (for all practical purposes) around February. The funny thing is that while on average the pandemic might end in India in February, we see that for specific regions the slope is actually increasing (which suggests the pandemic might never end).
And this creates confusion. When you have a bunch of regions with upward slopes, and then suddenly for the aggregate (India) it is a downward slope, it doesn’t make intuitive sense. It is similar to Simpson’s paradox, where a trend disappears when you aggregate data. This graph possibly represents the most famous example of Simpson’s paradox.
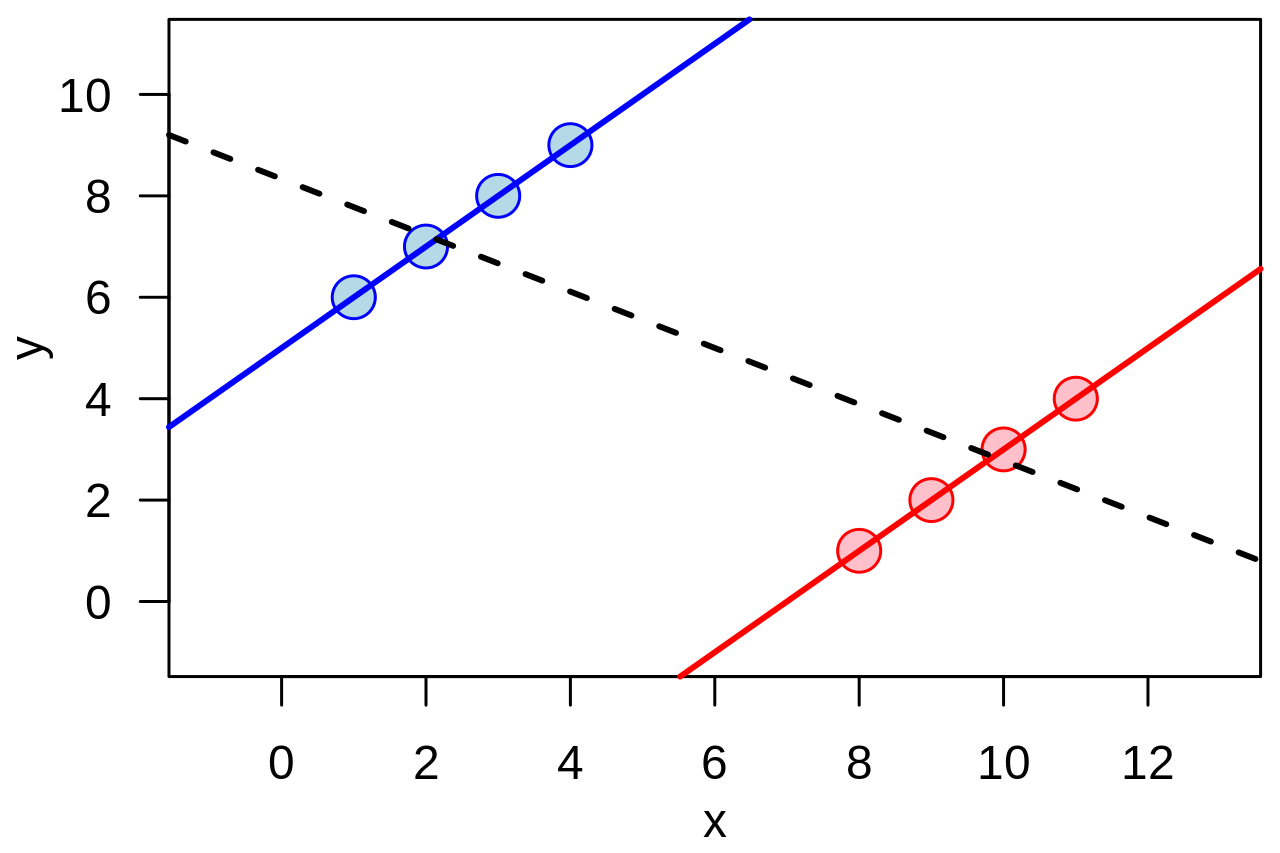
Back to the Levitt’s metric, my only explanation is that the curve can’t be infinitely upward sloping – the number of people in any place is finite and so the disease is bound to die out some time or the other. The upward sloping lines are only a figment of the arbitrary linear extrapolation, and are likely to turn down sooner rather than later.