In July 2004, I went to Madras, wore fancy clothes and collected a laminated piece of paper. The piece of paper, formally called “Bachelor of Technology”, certified three things.
First, it said that I had (very likely) got a very good rank in IIT JEE, which enabled me to enrol in the Computer Science B.Tech. program at IIT Madras. Then, it certified that I had attended a certain number of lectures and laboratories (equivalent to “180 credits”) at IIT Madras. Finally, it certified that I had completed assignments and passed tests administered by IIT Madras to a sufficient degree that qualified me to get the piece of paper.
Note that all these three were necessary conditions to my getting my degree from IIT Madras. Not passing IIT JEE with a fancy enough rank would have precluded me from the other two steps in the first place. Either not attending lectures and labs, or not doing the assignments and exams, would have meant that my “coursework would be incomplete”, leaving me ineligible to get the degree.
In other words, my higher education was bundled. There is no reason that should be so.
There is no reason that a single entity should have been responsible for entry testing (which is what IIT-JEE essentially is), teaching and exit testing. Each of these three could have been done by an independent entity.
For example, you could have “credentialing entities” or “entry testing entities”, whose job is to test you on things that admissions departments of colleges might test you on. This could include subject tests such as IIT-JEE, or aptitude tests such as GRE, or even evaluations of extra-curricular activities, recommendation letters and essays as practiced in American universities.
Then, you could have “teaching entities”. This is like the MOOCs we already have. The job of these teaching entities is to teach a subject or set of subjects, and make sure you understood your stuff. Testing whether you had learnt the stuff, however, is not the job of the teaching entities. It is also likely that unless there are superstar teachers, the value of these teaching entities comes down, on account of marginal cost pricing, close to zero.
To test whether you learnt your stuff, you have the testing entities. Their job is to test whether your level of knowledge is sufficient to certify that you have learnt a particular subject. It is well possible that some testing entities might demand that you cleared a particular cutoff on entry tests before you are eligible to get their exit test certificates, but many others may not.
The only downside of this unbundling is that independent evaluation becomes difficult. What do you make of a person who has cleared entry tests mandated by a certain set of institutions, and exit tests traditionally associated with a completely different set of institutions? Is the entry test certificate (and associated rank or percentile) enough to give you a particular credential or should it be associated with an exit test as well?
These complications are possibly why higher education hasn’t experimented with any such unbundling so far (though MOOCs have taken the teaching bit outside the traditional classroom).
However, there is an opportunity now. Covid-19 means that several universities have decided to have online-only classes in 2019-20. Without the peer learning aspect, people are wondering if it is worth paying the traditional amount for these schools. People are also calling for top universities to expand their programs since the marginal cost is slipping further, with the backlash being that this will “dilute” the degrees.
This is where unbundling comes into play. Essentially anyone should be able to attend the Harvard lectures, and maybe even do the Harvard exams (if this can be done with a sufficiently low marginal cost). However, you get a Harvard degree if and only if you have cleared the traditional Harvard admission criteria (maybe the rest get a diploma or something?).
Some other people might decide upon clearing the traditional Harvard admission criteria that this credential itself is sufficient for them and not bother getting the full degree. The possibilities are endless.
Old-time readers of this blog might remember that I had almost experimented with something like this. Highly disillusioned during my first year at IIT, I had considered dropping out, reasoning that my JEE rank was credential enough. Finally, I turned out to be too much of a chicken to do that.

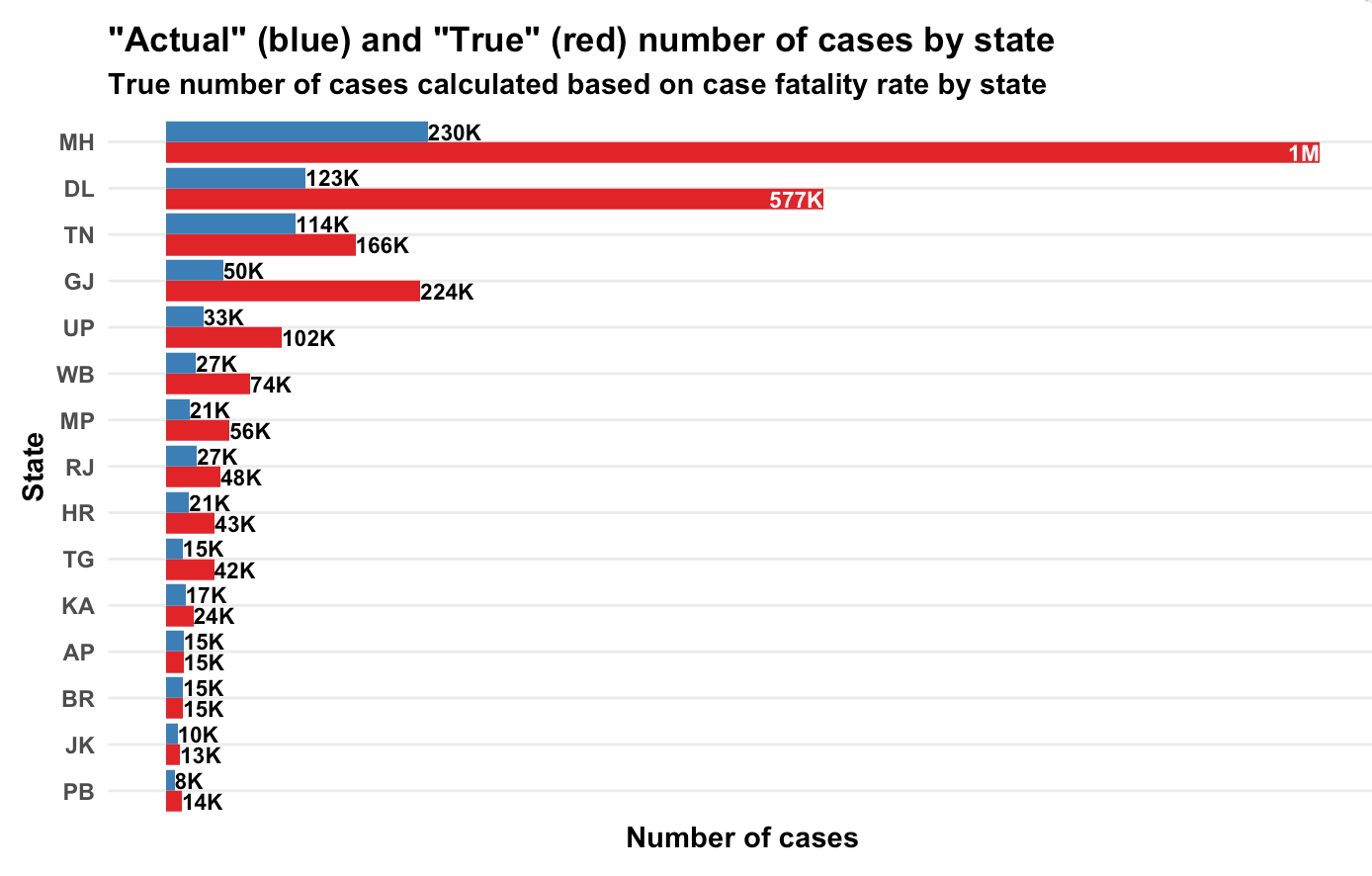
 of all the confirmed cases will die. We assume an average number of days (
of all the confirmed cases will die. We assume an average number of days ( ) to death for people who are supposed to die (let’s call them
) to death for people who are supposed to die (let’s call them  dies each day. Of everyone who is infected, supposed to die and not yet dead, a proportion
dies each day. Of everyone who is infected, supposed to die and not yet dead, a proportion  . So if people are supposed to die in an average of 20 days,
. So if people are supposed to die in an average of 20 days, 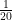 will die today,
will die today, 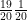 will die tomorrow. And so on.
will die tomorrow. And so on. days back are going to die today. Do this for all
days back are going to die today. Do this for all  is the number of people who die on day
is the number of people who die on day  and
and  is the number of cases confirmed on day
is the number of cases confirmed on day 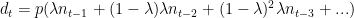
 s are known.
s are known. 

