A week ago, I put a post on LinkedIn saying if someone else working in analytics / data science primarily uses R for their work, I would like to chat.
I got two responses, one of which was from a guy who strictly isn’t in analytics / data science, but needs to analyse large amounts of data for his work. I had a long chat with the other guy today.
Yesterday I put the same post on Twitter, and have got a few more responses from there. However, it is staggering. An overwhelming majority of data people who I know work in Python. One of the reasons I put these posts was to assure myself that I’m not alone in using R, though the response so far hasn’t given me too much of an assurance.
So why do most companies end up using Python for analytics, even when R is clearly better for things like data wrangling, reporting, visualisation, dashboarding, etc.? I have a few theories on this, and I think all of them come together to result in python having its “overwhelming marketshare” (at least among people I know).
Tech people clearly prefer python since it’s easier to integrate. So the tech leaders request the data science leaders to use Python, since it is much easier for the tech people. In a lot of organisations, data science reports into tech, so this request is honoured.
Even if it isn’t, if you recall, “data scientists” are generally tech facing rather than business facing. This means that the models they build need to be codified, and added to the company’s code base. This means necessarily working together with tech, and this means using a programming language that tech is comfortable with.
Then, this spills over. Usually, someone has the bright idea that the firm shouldn’t use two languages for what is essentially the same thing. And so the analytics people are also forced to use python for their analytics, even if it isn’t built for the purpose. And then it spreads.
Next is the “cool factor”. There is this impression that the more technical a solution is, the more superior it is, even if it has no direct business impact (an employer had once told me, “I have raised money saying we are using machine learning. If our investors see the algorithms you’re proposing, they’ll want their money back”).
So a youngster getting into data wants to do “all the latest stuff”. This means machine learning. Deep learning. Reinforcement learning. And all that. There is an impression that this kind of work is “better work” compared to let’s say generating business insights using data. And in general, the packages for machine learning have traditionally been easier in Python than they are in R (though R is fast catching up, and in general python is far behind R when it comes to user friendliness).
Then, the growth in data and jobs associated with it such as machine learning or data engineering have meant that a lot of formerly tech people have got into data work. Python is fundamentally a programming language, with a package (pandas) added on to do data work. Techies find it far more intuitive than R, which is fundamentally a statistical software. On the other hand, people who are coming from a business / Excel background find it far more comfortable to use R. Python can be intimidating (I fall in this bucket).
So yeah – the tech integration, the number of tech people who are coming into data and the “cool factor” associated with the more techie stuff means that Python is gaining, at R’s expense (in my circle at least).
In any case I’m going to continue to use R. I’m at least 10X faster in R than I am in Python, and having used R for 12 years now, I’m too used to that way of working to change things up.

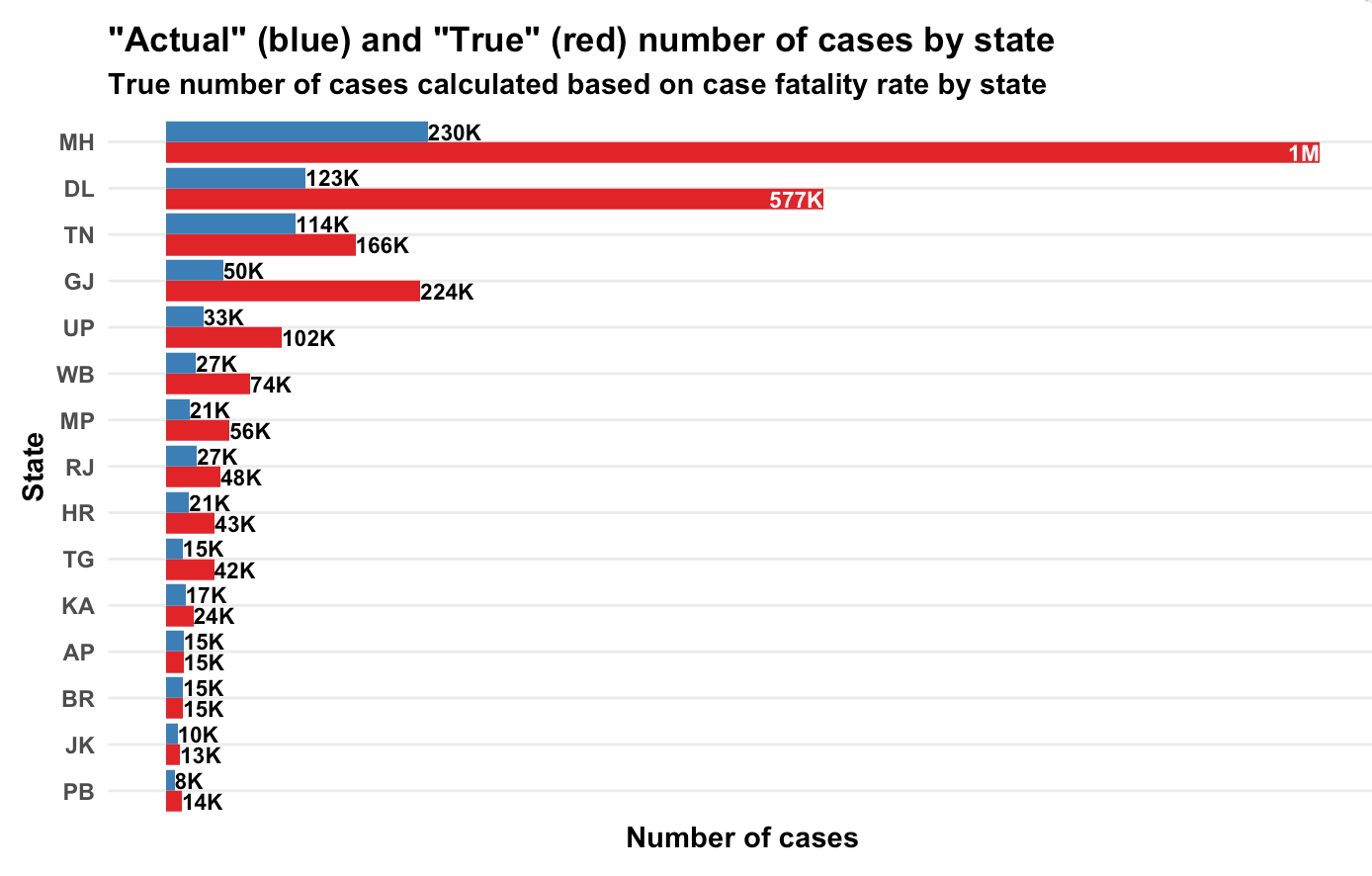
 of all the confirmed cases will die. We assume an average number of days (
of all the confirmed cases will die. We assume an average number of days ( ) to death for people who are supposed to die (let’s call them
) to death for people who are supposed to die (let’s call them  dies each day. Of everyone who is infected, supposed to die and not yet dead, a proportion
dies each day. Of everyone who is infected, supposed to die and not yet dead, a proportion  . So if people are supposed to die in an average of 20 days,
. So if people are supposed to die in an average of 20 days, 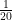 will die today,
will die today, 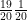 will die tomorrow. And so on.
will die tomorrow. And so on. days back are going to die today. Do this for all
days back are going to die today. Do this for all  is the number of people who die on day
is the number of people who die on day  and
and  is the number of cases confirmed on day
is the number of cases confirmed on day 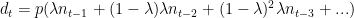
 s are known.
s are known. 

{kind=link}
{kind=link}