For most of my life, I pretty much haven’t understood what the point of “recreating” is. For example, in school if someone says they were going to “act out ______’s _____” I would wonder what the point of it was – that story is well known so they might as well do something more creative.
Later on in life, maybe some 12-13 years back, I discovered the joy in “retelling known stories” – since everyone knows the story you can be far more expressive in how you tell it. Still, however, just “re-creation” (not recreation) never really fascinated me. Most of the point of doing things is to do them your way, I’ve believed (and nowadays, if you think of it, most re-creating can be outsourced to a generative AI).
And the this weekend that changed. On Saturday, I made the long-pending trip to Blossom (helped that daughter had a birthday party to attend nearby), and among other things, I bought Edward Tufte’s classic “The Visual Display of Quantitative Information“. I had read a pirated PDF of this a decade ago (when I was starting out in “data science”), but always wanted the “real thing”.
And this physical copy, designed by Tufte himself, is an absolute joy to read. And I’m paying more attention to the (really beautiful) graphics. So, when I came across this chart of New York weather, I knew I had to recreate it.

A few months earlier, I had dowloaded the dataset for Bangalore’s hourly temperature and rainfall since 1981 (i.e. a bit longer than my own life). This dataset ended in November 2022, but I wasn’t concerned. Basically, this is such a large and complex dataset that so far I had been unable to come up with an easy way to visualise it. So, when I saw this thing from Tufte, recreating would be a good idea.
I spent about an hour and half yesterday doing this. I’ve ignored the colour schemes and other “aesthetic” stuff (just realised I’ve not included the right axis in my re-creation). But I do think I’ve got something fairly good.

2022 was an unusual weather year for Bangalore and it shows in this graph. May wasn’t as hot as usual, and there were some rather cold days. Bangalore recorded its coldest October and November days since the 90s (though as this graph shows, not a record by any means). It was overall a really wet year, constantly raining from May to November. The graph shows all of it.
Also if you look at the “noraml pattern” and the records, you see Bangalore’s unusual climate (yes, I do mean “climate” and not “weather” here). Thanks to the monsoons (and pre-monsoons), April is the hottest month. Summer, this year, has already started – in the afternoons it is impossible to go out now. The minimum temperatures are remarkably consistent through the year (so except early in the mornings, you pretty much NEVER need a sweater here – at least I haven’t after I moved back from London).
There is so much more I can do. I’m glad to have come across a template to analyse the data using. Whenever I get the enthu (you know what this website is called) I’ll upload my code to produce this graph onto github or something. And when I get more enthu, I’ll make it aesthetically similar to Tufte’s graph (and include December 2022 data as well).





 , the area of the polygon thus formed equals
, the area of the polygon thus formed equals  . It is not hard to see that for any value of
. It is not hard to see that for any value of 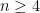 , the ordering of the “axes” makes a material difference in the area of the chart.
, the ordering of the “axes” makes a material difference in the area of the chart.