There has been a massive jump in the number of covid-19 positive cases in Karnataka over the last couple of days. Today, there were 44 new cases discovered, and yesterday there were 36. This is a big jump from the average of about 15 cases per day in the preceding 4-5 days.
The good news is that not all of this is new infection. A lot of cases that have come out today are clusters of people who have collectively tested positive. However, there is one bit from yesterday’s cases (again a bunch of clusters) that stands out.

I guess by now everyone knows what “travelled from Delhi” is a euphemism for. The reason they are interesting to me is that they are based on a “repeat test”. In other words, all these people had tested negative the first time they were tested, and then they were tested again yesterday and found positive.
Why did they need a repeat test? That’s because the sensitivity of the Covid-19 test is rather low. Out of every 100 infected people who take the test, only about 70 are found positive (on average) by the test. That also depends upon when the sample is taken. From the abstract of this paper:
Over the four days of infection prior to the typical time of symptom onset (day 5) the probability of a false negative test in an infected individual falls from 100% on day one (95% CI 69-100%) to 61% on day four (95% CI 18-98%), though there is considerable uncertainty in these numbers. On the day of symptom onset, the median false negative rate was 39% (95% CI 16-77%). This decreased to 26% (95% CI 18-34%) on day 8 (3 days after symptom onset), then began to rise again, from 27% (95% CI 20-34%) on day 9 to 61% (95% CI 54-67%) on day 21.
About one in three (depending upon when you draw the sample) infected people who have the disease are found by the test to be uninfected. Maybe I should state it again. If you test a covid-19 positive person for covid-19, there is almost a one-third chance that she will be found negative.
The good news (at the face of it) is that the test has “high specificity” of about 97-98% (this is from conversations I’ve had with people in the know. I’m unable to find links to corroborate this), or a false positive rate of 2-3%. That seems rather accurate, except that when the “prior probability” of having the disease is low, even this specificity is not good enough.
Let’s assume that a million Indians are covid-19 positive (the official numbers as of today are a little more than one-hundredth of that number). With one and a third billion people, that represents 0.075% of the population.
Let’s say we were to start “random testing” (as a number of commentators are advocating), and were to pull a random person off the street to test for Covid-19. The “prior” (before testing) likelihood she has Covid-19 is 0.075% (assume we don’t know anything more about her to change this assumption).
If we were to take 20000 such people, 15 of them will have the disease. The other 19985 don’t. Let’s test all 20000 of them.
Of the 15 who have the disease, the test returns “positive” for 10.5 (70% accuracy, round up to 11). Of the 19985 who don’t have the disease, the test returns “positive” for 400 of them (let’s assume a specificity of 98% (or a false positive rate of 2%), placing more faith in the test)! In other words, if there were a million Covid-19 positive people in India, and a random Indian were to take the test and test positive, the likelihood she actually has the disease is 11/411 = 2.6%.
If there were 10 million covid-19 positive people in India (no harm in supposing), then the “base rate” would be .75%. So out of our sample of 20000, 150 would have the disease. Again testing all 20000, 105 of the 150 who have the disease would test positive. 397 of the 19850 who don’t have the disease will test positive. In other words, if there were ten million Covid-19 positive people in India, and a random Indian were to take the test and test positive, the likelihood she actually has the disease is 105/(397+105) = 21%.
If there were ten million Covid-19 positive people in India, only one-fifth of the people who tested positive in a random test would actually have the disease.
Take a sip of water (ok I’m reading The Ken’s Beyond The First Order too much nowadays, it seems).
This is all standard maths stuff, and any self-respecting book or course on probability and Bayes’s Theorem will have at least a reference to AIDS or cancer testing. The story goes that this was a big deal in the 1990s when some people suggested that the AIDS test be used widely. Then, once this problem of false positives and posterior probabilities was pointed out, the strategy of only testing “high risk cases” got accepted.
And with a “low incidence” disease like covid-19, effective testing means you test people with a high prior probability. In India, that has meant testing people who travelled abroad, people who have come in contact with other known infected, healthcare workers, people who attended the Tablighi Jamaat conference in Delhi, and so on.
The advantage with testing people who already have a reasonable chance of having the disease is that once the test returns positive, you can be pretty sure they actually have the disease. It is more effective and efficient. Testing people with a “high prior probability of disease” is not discriminatory, or a “sampling bias” as some commentators alleged. It is prudent statistical practice.
Again, as I found to my own detriment with my tweetstorm on this topic the other day, people are bound to see politics and ascribe political motives to everything nowadays. In that sense, a lot of the commentary is not surprising. It’s also not surprising that when “one wing” heavily retweeted my article, “the other wing” made efforts to find holes in my argument (which, again, is textbook math).
One possibly apolitical criticism of my tweetstorm was that “the purpose of random testing is not to find out who is positive. It is to find out what proportion of the population has the disease”. The cost of this (apart from the monetary cost of actually testing) are threefold. Firstly, a large number of uninfected people will get hospitalised in covid-specific hospitals, clogging hospital capacity and increasing the chances that they get infected while in hospital.
Secondly, getting a truly random sample in this case is tricky, and possibly unethical. When you have limited testing capacity, you would be inclined (possibly morally, even) to use it on people who already have a high prior probability.
Finally, when the incidence is small, we need a really large sample to find out the true range.
Let’s say 1 in 1000 Indians have the disease (or about 1.35 million people). Using the Chi Square test of proportions, our estimate of the incidence of the disease varies significantly on how many people are tested.
If we test a 1000 people and find 1 positive, the true incidence of the disease (95% confidence interval) could be anywhere from 0.01% to 0.65%.
If we test 10000 people and find 10 positive, the true incidence of the disease could be anywhere between 0.05% and 0.2%.
Only if we test 100000 people (a truly massive random sample) and find 100 positive, then the true incidence lies between 0.08% and 0.12%, an acceptable range.
I admit that we may not be testing enough. A simple rule of thumb is that anyone with more than a 5% prior probability of having the disease needs to be tested. How we determine this prior probability is again dependent on some rules of thumb.
I’ll close by saying that we should NOT be doing random testing. That would be unethical on multiple counts.

 is a parameter of transmission – the higher it is, the more likely the disease with transmit (holding the amount of time spent together constant).
is a parameter of transmission – the higher it is, the more likely the disease with transmit (holding the amount of time spent together constant).
 of the population is infected, and we assume that the shopkeeper is uninfected.
of the population is infected, and we assume that the shopkeeper is uninfected.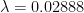 , for a two minute interaction, the probability of transmission is
, for a two minute interaction, the probability of transmission is 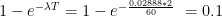 %.
%.












 We see that if Liverpool replicate their results from last season for the rest of the fixtures, they should win the league comfortably.
We see that if Liverpool replicate their results from last season for the rest of the fixtures, they should win the league comfortably.{kind=link}