I must warn that this is a super long post. Also I wonder if I should put this on medium in order to get more footage.
Most models of disease spread use what is known as a “SIR” framework. This Numberphile video gives a good primer into this framework.
The problem with the framework is that it’s too simplistic. It depends primarily on one parameter “R0”, which is the average number of people that each infected patient infects. When R0 is high, each patient infects a number of other people, and the disease spreads fast. With a low R0, the disease spreads slow. It was the SIR model that was used to produce all those “flatten the curve” pictures that we were bombarded with a week or two back.
There is a second parameter as well – the recovery or removal rate. Some diseases are so lethal that they have a high removal rate (eg. Ebola), and this puts a natural limit on how much the disease can spread, since infected people die before they can infect too many people.
In any case, such modelling is great for academic studies, and post-facto analyses where R0 can be estimated. As we are currently in the middle of an epidemic, this kind of simplistic modelling can’t take us far. Nobody has a clue yet on what the R0 for covid-19 is. Nobody knows what proportion of total cases are asymptomatic. Nobody knows the mortality rate.
And things are changing well-at-a-faster-rate. Governments are imposing distancing of various forms. First offices were shut down. Then shops were shut down. Now everything is shut down, and many of us have been asked to step out “only to get necessities”. And in such dynamic and fast-changing environments, a simplistic model such as the SIR can only take us so far, and uncertainty in estimating R0 means it can be pretty much useless as well.
In this context, I thought I’ll simulate a few real-life situations, and try to model the spread of the disease in these situations. This can give us an insight into what kind of services are more dangerous than others, and how we could potentially “get back to life” after going through an initial period of lockdown.
The basic assumption I’ve made is that the longer you spend with an infected person, the greater the chance of getting infected yourself. This is not an unreasonable assumption because the spread happens through activities such as sneezing, touching, inadvertently dropping droplets of your saliva on to the other person, and so on, each of which is more likely the longer the time you spend with someone.
Some basic modelling revealed that this can be modelled as a sort of negative exponential curve that looks like this.

T is the number of hours you spend with the other person. 
The function looks like this: 
We have no clue what
This gives the value of
-
Delivery
This is the simplest model I built. There is one shop, and N customers. Customers come one at a time and spend a fixed amount of time (1 or 2 or 5 minutes) at the shop, which has one shopkeeper. Initially, a proportion 
And then we model the transmission – based on our 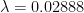
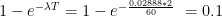
In hindsight, I realised that this kind of a set up better describes “delivery” than a shop. With a 0.1% probability the delivery person gets infected from an infected customer during a delivery. With the same probability an infected delivery person infects a customer. The only way the disease can spread through this “shop” is for the shopkeeper / delivery person to be uninfected.
How does it play out? I simulated 10000 paths where one guy delivers to 1000 homes (maybe over the course of a week? that doesn’t matter as long as the overall infected rate in the population otherwise is constant), and spends exactly two minutes at each delivery, which is made to a single person. Let’s take a few cases, with different base cases of incidence of the disease – 0.1%, 0.2%, 0.5%, 1%, 2%, 5%, 10%, 20% and 50%.
The number of NEW people infected in each case is graphed here (we don’t care how many got the disease otherwise. We’re modelling how many got it from our “shop”). The right side graph excludes the case of zero new infections, just to show you the scale of the problem.

Notice this – even when 50% of the population is infected, as long as the shopkeeper or delivery person is not initially infected, the chances of additional infections through 2-minute delivery are MINUSCULE. A strong case for policy-makers to enable delivery of all kinds, essential or inessential.
2. SHOP
Now, let’s complicate matters a little bit. Instead of a delivery person going to each home, let’s assume a shop. Multiple people can be in the shop at the same time, and there can be more than one shopkeeper.
Let’s use the assumptions of standard queueing theory, and assume that the inter-arrival time for customers is guided by an Exponential distribution, and the time they spend in the shop is also guided by an Exponential distribution.
At the time when customers are in the shop, any infected customer (or shopkeeper) inside can infect any other customer or shopkeeper. So if you spend 2 minutes in a shop where there is 1 infected person, our calculation above tells us that you have a 0.1% chance of being infected yourself. If there are 10 infected people in the shop and you spend 2 minutes there, this is akin to spending 20 minutes with one infected person, and you have a 1% chance of getting infected.
Let’s consider two or three scenarios here. First is the “normal” case where one customer arrives every 5 minutes, and each customer spends 10 minutes in the shop (note that the shop can “serve” multiple customers simultaneously, so the queue doesn’t blow up here). Again let’s take a total of 1000 customers (assume a 24/7 open shop), and one shopkeeper.

Notice that there is significant transmission of infection here, even though we started with 5% of the population being infected. On average, another 3% of the population gets infected! Open supermarkets with usual crowd can result in significant transmission.
Does keeping the shop open with some sort of social distancing (let’s see only one-fourth as many people arrive) work? So people arrive with an average gap of 20 minutes, and still spend 10 minutes in the shop. There are still 10 shopkeepers. What does it look like when we start with 5% of the people being infected?
The graph is pretty much identical so I’m not bothering to put that here!
3. Office
This scenario simulates for N people who are working together for a certain number of hours. We assume that exactly one person is infected at the beginning of the meeting. We also assume that once a person is infected, she can start infecting others in the very next minute (with our transmission probability).
How does the infection grow in this case? This is an easier simulation than the earlier one so we can run 10000 Monte Carlo paths. Let’s say we have a “meeting” with 40 people (could just be 40 people working in a small room) which lasts 4 hours. If we start with one infected person, this is how the number of infected grows over the 4 hours.

{kind=link}
The spread is massive! When you have a large bunch of people in a small closed space over a significant period of time, the infection spreads rapidly among them. Even if you take a 10 person meeting over an hour, one infected person at the start can result in an average of 0.3 other people being infected by the end of the meeting.
10 persons meeting over 8 hours (a small office) with one initially infected means 3.5 others (on average) being infected by the end of the day.
Offices are dangerous places for the infection to spread. Even after the lockdown is lifted, some sort of work from home regulations need to be in place until the infection has been fully brought under control.
4. Conferences
This is another form of “meeting”, except that at each point in time, people don’t engage with the whole room, but only a handful of others. These groups form at random, changing every minute, and infection can spread only within a particular group.
Let’s take a 100 person conference with 1 initially infected person. Let’s assume it lasts 8 hours. Depending upon how many people come together at a time, the spread of the infection rapidly changes, as can be seen in the graph below.
If people talk two at a time, there’s a 63% probability that the infection doesn’t spread at all. If they talk 5 at a time, this probability is cut by half. And if people congregate 10 at a time, there’s only a 11% chance that by the end of the day the infection HASN’T propagated!

One takeaway from this is that even once offices start functioning, they need to impose social distancing measures (until the virus has been completely wiped out). All large-ish meetings by video conference. A certain proportion of workers working from home by rotation.
And I wonder what will happen to the conferences.
I’ve put my (unedited) code here. Feel free to use and play around.
Finally, you might wonder why I’ve made so many Monte Carlo Simulations. Well, as the great Matt Levine had himself said, that’s my secret sauce!
One thought on “Simulating Covid-19 Scenarios”