So I got an award today. It is called “exemplary data scientist”, and was given out by the Analytics India Magazine as part of their MachineCon 2022. I didn’t really do anything to get the award, apart from existing in my current job.
I guess having been out of the corporate world for nearly a decade, I had so far completely missed out on the awards and conferences circuit. I would see old classmates and colleagues put pictures on LinkedIn collecting awards. I wouldn’t know what to make of it when my oldest friend would tell me that whenever he heard “eye of the tiger”, he would mentally prepare to get up and go receive an award (he got so many I think). It was a world alien to me.
Parallelly, I used to crib about how while I’m well networked in India, and especially in Bangalore, my networking within the analytics and data science community is shit. In a way, I was longing for physical events to remedy this, and would lament that the pandemic had killed those.
So I was positively surprised when about a month ago Analytics India Magazine wrote to me saying they wanted to give me this award, and it would be part of this in-person conference. I knew of the magazine, so after asking around a bit on legitimacy of such awards and looking at who had got it the last time round, I happily accepted.
Most of the awardees were people like me – heads of analytics or data science at some company in India. And my hypothesis that my networking in the industry was shit was confirmed when I looked at the list of attendees – of 100 odd people listed on the MachineCon website, I barely knew 5 (of which 2 didn’t turn up at the event today).
Again I might sound like a n00b, but conferences like today are classic two sided markets (read this eminently readable paper on two sided markets and pricing of the same by Jean Tirole of the University of Toulouse). On the one hand are awardees – people like me and 99 others, who are incentivised to attend the event with the carrot of the award. On the other hand are people who want to meet us, who will then pay to attend the event (or sponsor it; the entry fee for paid tickets to the event was a hefty $399).
It is like “ladies’ night” that pubs have, where on a particular days of the week, women who go to the pub get a free drink. This attracts women, which in turn attracts men who seek to court the women. And what the pub spends in subsidising the women it makes back in terms of greater revenue from the men on the night.
And so it was at today’s conference. I got courted by at least 10 people, trying to sell me cloud services, “AI services on the cloud”, business intelligence tools, “AI powered business intelligence tools”, recruitment services and the like. Before the conference, I had received LinkedIn requests from a few people seeking to sell me stuff at the conference. In the middle of the conference, I got a call from an organiser asking me to step out of the hall so that a sponsor could sell to me.
I held a poker face with stock replies like “I’m not the person who makes this purchasing decision” or “I prefer open source tools” or “we’re building this in house”.
With full benefit of hindsight, Radisson Blu in Marathahalli is a pretty good conference venue. An entire wing of the ground floor of the hotel is dedicated for events, and the AIM guys had taken over the place. While I had not attended any such event earlier, it had all the markings of a well-funded and well-organised event.
As I entered the conference hall, the first thing that struck me was the number of people in suits. Most people were in suits (though few wore ties; And as if the conference expected people to turn up in suits, the goodie bag included a tie, a pair of cufflinks and a pocket square). And I’m just not used to that. Half the days I go to office in shorts. When I feel like wearing something more formal, I wear polo T-shirts with chinos.
My colleagues who went to the NSE last month to ring the bell to take us public all turned up company T-shirts and jeans. And that’s precisely what I wore to the conference today, though I had recently procured a “formal uniform” (polo T-shirt with company logo, rather than my “usual uniform” which is a round neck T-shirt). I was pretty much the only person there in “uniform”. Towards the end of the day, I saw one other guy in his company shirt, but he was wearing a blazer over it!
Pretty soon I met an old acquaintance (who I hadn’t known would be at the conference). He introduced me to a friend, and we went for coffee. I was eating a cookie with the coffee, and had an insight – at conferences, you should eat with your left hand. That way, you don’t touch the food with the same hand you use to touch other people’s hands (surprisingly I couldn’t find sanitiser dispensers at the venue).
The talks, as expected, were nothing much to write about. Most were by sponsors selling their wares. The one talk that wasn’t by a sponsor was delivered by a guy who was introduced as “his greatgrandfather did this. His grandfather did that. And now this guy is here to talk about ethics of AI”. Full Challenge Gopalakrishna feels happened (though, unfortunately, the Kannada fellows I’d hung out with earlier that day hadn’t watched the movie).
I was telling some people over lunch (which was pretty good) that talking about ethics in AI at a conference has become like worshipping Ganesha as part of any elaborate pooja. It has become the de riguer thing to do. And so you pay obeisance to the concept and move on.
Ok so i'm really really annoyed by all this focus on "ethical AI". It is just driven by "social desirability bias". Talking about ethical AI seemingly makes you look ethical so people talk about it. fund research in it. etc.
— Karthik S (@karthiks) March 27, 2022
The awards function had three sections. The first section was for “users of AI” (from what I understood). The second (where I was included) was for “exemplary data scientists”. I don’t know what the third was for (my wife is ill today so I came home early as soon as I’d collected my award), except that it would be given by fast bowler and match referee Javagal Srinath. Most of the people I’d hung out with through the day were in the Srinath section of the awards.
Overall it felt good. The drive to Marathahalli took only 45 minutes each way (I drove). A lot of people had travelled from other cities in India to reach the venue. I met a few new people. My networking in data science and analytics is still not great, but far better than it used to be. I hope to go for more such events (though we need to figure out how to do these events without that talks).
PS: Everyone who got the award in my section was made to line up for a group photo. As we posed with our awards, an organiser said “make sure all of you hold the prizes in a way that the Intel (today’s chief sponsor) logo faces the camera”. “I guess they want Intel outside”, I joked. It seemed to be well received by the people standing around me. I didn’t talk to any of them after that, though.



 musicians who need to coordinate, you have
musicians who need to coordinate, you have  pairs of people who need to coordinate. When
pairs of people who need to coordinate. When  grows well-at-a-faster-rate. And that is a problem, and a risk.
grows well-at-a-faster-rate. And that is a problem, and a risk.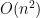 problem has become an
problem has become an  problem!
problem!