For a long time I used to wonder why orchestras have conductors. I possibly first noticed the presence of the conductor sometime in the 1990s when Zubin Mehta was in the news. And then I always wondered why this person, who didn’t play anything but stood there waving a stick, needed to exist. Couldn’t the orchestra coordinate itself like rockstars or practitioners of Indian music forms do?
And then i came across this video a year or two back.
And then the computer science training I’d gone through two decades back kicked in – the job of an orchestra conductor is to reduce an O(n^2) problem to an O(n) problem.
For a group of musicians to make music, they need to coordinate with each other. Yes, they have the staff notation and all that, but still they need to know when to speed up or slow down, when to make what transitions, etc. They may have practiced together but the professional performance needs to be flawless. And so they need to constantly take cues from each other.
When you have 


Enter the conductor. Rather than taking cues from one another, the musicians now simply need to take cues from this one person. And so there are now only 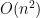

For whatever reason, while I was thinking about this yesterday, I got reminded of legendary finance professor R Vaidya‘s class on capital asset pricing model (CAPM), or as he put it “Sharpe single index model” (surprisingly all the links I find for this are from Indian test prep sites, so not linking).
We had just learnt portfolio theory, and how using the expected returns, variances and correlations between a set of securities we could construct an “efficient frontier” of securities that could give us the best risk-adjusted return. Seemed very mathematically elegant, except that in case you needed to construct a portfolio of
And then Vaidya introduced CAPM, which magically reduced the problem to an
In a sense, if you think about it, the index in CAPM is like the conductor of an orchestra. If only all
