Last evening we hosted a party at home. Like all parties we host, we used Graph Theory to plan this one. This time, however, we used graph theory in a very different way to how we normally use it – our intent was to avoid large cliques. And, looking back, I think it worked.
First, some back story. For some 3-4 months now we’ve been planning to have a party at home. There has been no real occasion accompanying it – we’ve just wanted to have a party for the heck of it, and to meet a few people.
The moment we started planning, my wife declared “you are the relatively more extrovert among the two of us, so organising this is your responsibility”. I duly put NED. She even wrote a newsletter about it.
The gamechanger was this podcast episode I listened to last month.
The episode, like a lot of podcast episodes, is related to this book that the guest has written. Something went off in my head as I listened to this episode on my way to work one day.
The biggest “bingo” moment was that this was going to be a strictly 2-hour party (well, we did 2.5 hours last night). In other words, “limited liability”!!
One of my biggest issues about having parties at my house is that sometimes guests tend to linger on, and there is no “defined end time”. For someone with limited social skills, this can be far more important than you think.
The next bingo was that this would be a “cocktail” party (meaning, no main course food). Again that massively brought down the cost of hosting – no planning menus, no messy food that would make the floor dirty, no hassles of cleaning up, and (most importantly) you could stick to your 2 / 2.5 hour limit without any “blockers”.
Listen to the whole episode. There are other tips and tricks, some of which I had internalised ahead of yesterday’s party. And then came the matter of the guest list.
I’ve always used graph theory (coincidentally my favourite subject from my undergrad) while planning parties. Typical use cases have been to ensure that the graph is connected (everyone knows at least one other person) and that there are no “cut vertices” (you don’t want the graph to get disconnected if one person doesn’t turn up).
This time we used it in another way – we wanted the graph to be connected but not too connected! The idea was that if there are small groups of guests who know each other too well, then they will spend the entirety of the party hanging out with each other, and not add value to the rest of the group.
Related to this was the fact that we had pre-decided that this party is not going to be a one-off, and we will host regularly. This made it easier to leave out people – we could always invite them the next time. Again, it is important that the party was “occasion-less” – if it is a birthday party or graduation party or wedding party or some such, people might feel offended that you left them out. Here, because we know we are going to do this regularly, we know “everyone’s number will come sometime”.
I remember the day we make the guest list. “If we invite X and Y, we cannot invite Z since she knows both X and Y too well”. “OK let’s leave out Z then”. “Take this guy’s name off the list, else there will be too many people from this hostel”. “I’ve met these two together several times, so we can call exactly one of them”. And so on.
With the benefit of hindsight, it went well. Everyone who said they will turn up turned up. There were fourteen adults (including us), which meant that there were at least three groups of conversation at any point in time – the “anti two pizza rule” I’ve written about. So a lot of people spoke to a lot of other people, and it was easy to move across groups.
I had promised to serve wine and kODbaLe, and kept it – kODbaLe is a fantastic party food in that it is large enough that you don’t eat too many in the course of an evening, and it doesn’t mess up your fingers. So no need of plates, and very little use of tissues. The wine was served in paper cups.
I wasn’t very good at keeping up timelines – maybe I drank too much wine. The party was supposed to end at 7:30, but it was 7:45 when I banged a spoon on a plate to get everyone’s attention and inform them that the party was over. In another ten minutes, everyone had left.


 “, I realised in my head, and decided this is a good time to teach my daughter binary search.
“, I realised in my head, and decided this is a good time to teach my daughter binary search. “? And went on to “is the number
“? And went on to “is the number  “, and got to the number in my wife’s mind (74) in exactly 7 guesses (and you might guess that
“, and got to the number in my wife’s mind (74) in exactly 7 guesses (and you might guess that  (90 is the number of 2 digit numbers) is 7).
(90 is the number of 2 digit numbers) is 7).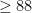 ?”
?”
 musicians who need to coordinate, you have
musicians who need to coordinate, you have  pairs of people who need to coordinate. When
pairs of people who need to coordinate. When  grows well-at-a-faster-rate. And that is a problem, and a risk.
grows well-at-a-faster-rate. And that is a problem, and a risk.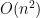 problem has become an
problem has become an  problem!
problem!