This is NOT a post about AI. It is, instead, about real intelligence.
My hypothesis is – the more you need to explain your decisions to people, the worse your decision-making gets.
Basically, instinct gets thrown out of the window.
Most of you who have worked in a company would have seen a few attempts at least of the company trying to be “more data driven”. Instead of making decisions on executives’ whims and will, they decide to set up a process with objective criteria. The decision is evaluated on each of these criteria and weights drawn up (if the weights are not known and you have a large number of known past decisions, this is just logistic regression). And then a sumproduct is computed, based on which the decision is made.
Now, I might be biased by the samples of this I’ve seen in real life (both in companies I’ve worked for and where I’ve been a consultant), but this kind of decision making usually results in the most atrocious decisions. And it is not even a problem with the criteria that are chosen or the weights each is assigned (so optimising this will get you nowhere). The problem is with the process.
As much as we would like to believe that the world is objective (and we are objective), we as humans are inherently instinctive and intuitive individuals (noticed that anupraas alankaar?). If we weren’t we wouldn’t have evolved as much as we have, since a very large part of the decisions we need to make need to be made quickly (running from a lion when you see one, for example, or braking when the car in front of you also brakes suddenly).
Quick decisions can never be made based on first principles – to be good at that, you need to have internalised the domain and the heuristics sufficiently, so that you know what to do.
I have this theory on why I didn’t do well in traditional strategy consulting (it was the first career I explored, and I left my job in three months) – it demanded way too much structure, and I had faked my way in. For all the interview cases, I would intuitively come up with a solution and then retrofit a “framework”. N-1 of the companies I applied to had possibly seen through this. One didn’t and took me in, and I left very soon.
What I’m trying to say is – when you try to explain your decisions, you are trying to be analytical about something you have instinctively come to the conclusion about, and with the analysis being “a way to convince the other person that I didn’t use my intuition”.
So when a bunch of people come up with their own retrofits on how they make the decision, the “process” that you come up with is basically a bunch of junk. And when you try to follow the process the next time, you end up with a random result.
The other issue with explaining decisions is that you try to come up with explanations that sound plausible and inoffensive. For example, you might interview someone (in person) and decide you don’t want to work with them because they have bad breath (perfectly valid, in my opinion, if you need to work closely with them – no pun intended). However, if you have to document your reason for rejection, this sounds too rude. So you say something rubbish like “he is overqualified for the role”.
At other times, you clearly don’t like the person you have spoken to but are unable to put your rejection reason in a polite manner, so you just reverse your decision and fail to reject the person. If everyone else also thinks the same as you (didn’t like but couldn’t find a polite enough reason to give, so failed to reject), through the “Monte Carlo process”, this person you clearly didn’t like ends up getting hired.
Yet another time, you might decide to write an algorithm for your decision (ok I promised to not talk about AI here, but anyways). You look at all the past decisions everyone has made in this context (and the reasons for those), and based on that, you build an algorithm. But then, if all these decisions have been made intuitively and the people’s documented decisions only retrofits, you are basing your algorithm on rubbish data. And you will end up with a rubbish algorithm (or a “data driven process”).
Actually – this even applies to artificial intelligence, but that is for another day.
The biggest problem with “explainable AI” is that the explanations usually look rather unintelligent.
Like YouTube recommending a video in a category “balls” for example
So best we don’t even try.
— Karthik S (@karthiks) July 9, 2022

 “, I realised in my head, and decided this is a good time to teach my daughter binary search.
“, I realised in my head, and decided this is a good time to teach my daughter binary search. “? And went on to “is the number
“? And went on to “is the number  “, and got to the number in my wife’s mind (74) in exactly 7 guesses (and you might guess that
“, and got to the number in my wife’s mind (74) in exactly 7 guesses (and you might guess that  (90 is the number of 2 digit numbers) is 7).
(90 is the number of 2 digit numbers) is 7).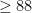 ?”
?” ), , 3 (
), , 3 ( ) and 2 (
) and 2 (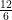 ) camels respectively. One camel was left over – the neighbour’s, who took it back.
) camels respectively. One camel was left over – the neighbour’s, who took it back.