The always excellent Matt Levine has reported in Bloomberg (with respect to the recent removal of the cap on the price of the Swiss Franc) that:
Goldman Sachs Chief Financial Officer Harvey Schwartz said on this morning’s earnings call that this was something like a 20-standard-deviation event
While mathematically this might be true, the question is if it makes sense at all. Since it is mathematically easy to model, traders look at volatility of an instrument in terms of its standard deviation. However, standard deviation is a good descriptor of a distribution only if the distribution looks something like a normal distribution. For all other distributions, it is essentially meaningless.
The more important point here is that the movement of the Swiss Franc (CHF) against the Euro had been artificially suppressed in the last three odd years. So from that perspective, whatever Standard Deviation would have been used in order to make the calculation was artificially low and essentially meaningless.
Instead, the way banks ought to have modelled it was in terms of modelling where EUR/CHF would end up in case the cap on the CHF was actually lifted (looking at capital and current flows between Switzerland and the Euro Area, this wouldn’t be hard to model), and then model the probability with which the Swiss National Bank would lift the cap on the Franc, and use the combination of the two to assess the risk in the CHF position. This way the embedded risk of the cap lifting, which was borne out on Thursday, could have been monitored and controlled, and possibly hedged.
There are a couple of other interesting stories connected to the lifting of the cap on the value of the CHF. The first has to do with Alpari, a UK-based FX trading house. The firm has had to declare insolvency following losses from Thursday. And as the company was going insolvent, they put out some interesting quotes. As the Guardian reports:
In the immediate aftermath of Thursday’s move by the Swiss central bank, analysts at Alpari had described the decision as “idiotic” and by Friday the firm had announced it was insolvent. “The recent move on the Swiss franc caused by the Swiss National Bank’s unexpected policy reversal of capping the Swiss franc against the euro has resulted in exceptional volatility and extreme lack of liquidity,” said Alpari.
The second story has to do with homeowners in Hungary and Poland who borrowed their home loans in Swiss Franc, and are now faced with significantly higher payments. I have little sympathy for these homeowners and less sympathy for the bankers who sold them the loans denominated in a foreign currency. I mean, who borrows in a foreign currency to buy a house? I don’t even …
There is a story related to that which is interesting, though. Though Hungary is more exposed to these loans than Poland, it is the Polish banks which are likely to suffer more from the appreciation in the CHF. The irony is that the Hungarian market was initially much more loosely regulated compared to the Polish market, where only wealthier people were allowed to borrow in CHF. But in Hungary, the regulator took more liberties in terms of forcing banks to take the hit on the exchange rate movement, and the loans were swapped back into the local currency a while back.
In related reading, check out this post by my Takshashila colleague Anantha Nageswaran on the crisis. I agree with most of it.





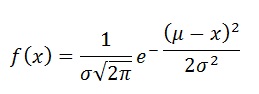
{kind=link}