Supposedly the latest (ok not that latest – it’s been around for a decade) thing in software engineering is this thing called “Agile programming“. It’s basically about breaking away from the old “waterfall model” (which we had learnt in a software engineering course back in 2003), and to a more iterative model with quick releases, updates, etc.
I’ve never worked as a software engineer, but it seems to me that Agile programming is the way to go – basically get something out and keep iterating till you have a good product rather than thinking endlessly about incorporating all design specifications before writing a single line of code. Requirements change rapidly nowadays, and unless you are “agile” (pun intended) to that, you will not produce good software.
Agile methodologies, however, don’t work in parliamentary procedures, since there is very high transaction cost there. Take, for example, the proposed Goods and Service Tax (GST). The current form of the Goods and Service Tax is an incredibly flawed bill, with taxes for movement of goods across states and certain products being excluded from the ambit altogether. Mihir Sharma at Business Standard has a great takedown of the current bill (there is no one quotable paragraph. Read the whole thing. I’m mostly in agreement).
So it seems to me that the government is passing the GST in its current half-baked form because it wants some version (like a Minimum Viable Product) off the ground, and then it hopes to rectify the shortcomings in a later iteration. In other words, the government is trying some sort of an agile methodology when it comes to passing the GST.
The problem with parliamentary procedures, however, is that transaction costs are great. Once a law has been passed, it is set in stone and the effort required for any single amendment is equal to the effort originally required for passing the law itself, since you have to go through the whole procedure again. In other words, our laws need to be developed using the waterfall model, and hence have full system requirement specifications in place before they are passed.
It’s not surprising since the procedure for passing laws was laid down back at a time when hardly any programming existed, leave alone agile programming. Yet, it begs the question of what can be done to make our laws more agile (pun intended).
PS: I understand that Agile software development has several features and this iterative nature is just one of them. But that is the only one I want to focus on here.
 and
and 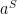 to the buyer and seller sides. The market for interactions between the two sides is one-sided if the volume V of transactions realized on the platform depends only on the aggregate price level
to the buyer and seller sides. The market for interactions between the two sides is one-sided if the volume V of transactions realized on the platform depends only on the aggregate price level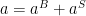
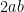 term” in the expansion of
term” in the expansion of  .
. ” term there implies that he thinks India and Canada’s interests are perfectly aligned (assuming a vector sum).
” term there implies that he thinks India and Canada’s interests are perfectly aligned (assuming a vector sum). . We can choose the unit in which we express utility such that we can set
. We can choose the unit in which we express utility such that we can set  , which means that the value of the network is
, which means that the value of the network is  .
. users on the first internet, and
users on the first internet, and  users on the second (this is bad nomenclature according to mathematical convention, where a and b are not used for integer variables, but there is a specific purpose here, as we can see). What is the total value of the internet(s)?
users on the second (this is bad nomenclature according to mathematical convention, where a and b are not used for integer variables, but there is a specific purpose here, as we can see). What is the total value of the internet(s)?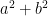 . Now, if we were to tear down the walls, and combine the two internets into one, what will be the total value? Now that we have one network of
. Now, if we were to tear down the walls, and combine the two internets into one, what will be the total value? Now that we have one network of  users, the value of the network is
users, the value of the network is  or
or 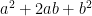 . So what is the additional benefit that we can get by imposing net neutrality, which means that we will have one internet?
. So what is the additional benefit that we can get by imposing net neutrality, which means that we will have one internet?  , of course!
, of course!