Talk to any analytics or “business intelligence” provider – be it a large commoditized outsourcing firm or a rather niche consultant – and one thing they all claim to advise their clients on is strategies for “cross sell”. However, my personal experience suggests that implementation of cross-sell strategies among retailers I encounter is extremely poor. I will illustrate two such examples in this post here.
Jet Airways and American Express together have come up with this “Jet Airways American Express Platinum Credit Card”. Like any other co-branded credit card, it offers you additional benefits on Jet Airways flights booked with this card (in terms of higher points) as well as some other benefits such as lounge access for economy travel. Given that I’m a consultant and travel frequently, this is something I think is good to have, and have attempted to purchase it a few times. And got discouraged by the purchase process each time and backed out.
Now, I’m a customer of both Jet Airways and American Express. I hold an American Express Gold Card (perhaps one of the few people to have an individual AmEx card), and have a Jet Privilege account. Yet, neither Jet or Amex seems remotely interested in selling to me. I once remember applying for this card through the Amex call centre. The person at the other end of the line wanted me to fill up the entire form once again – despite me being already a cardholder. This I would ascribe to messed up incentive structures where the salesperson at the other end gets higher benefits for acquiring a new customer rather than upgrading an existing one. I’ve mentioned I want this card to the Amex call centre several times, yet no one has called me back.
However, these are not the missed cross-sell opportunities I’m talking about in this post. Three times in the last three months (maybe more, but I cannot recollect) I’ve booked an air ticket to fly on Jet airways from the Jet Airways website having logged into my Jet Privilege account and paying with my American Express card. Each time I’ve waited hopefully that some system at either the Jet or the Amex end will make the connection and offer me this Platinum card, but so far there has been response. It is perhaps the case that for some reason they do not want to upgrade existing customers to this card (in which case the entire discussion is moot) but not offering me a card here is simply a case of a blatant missed opportunity – in cricketing terms you can think of this as an easy dropped catch.
The other case has to do with banking. I’m in the process of purchasing a house, and over the last few months have been transferring large amounts of money to the seller in order to make my down payments (which I’m meeting through my savings). Now, I’ve had my account with Citibank for over seven years and have never withdrew such large amounts – except maybe to make some fixed deposits. One time, I got a call from the bank’s call centre, confirming if it was indeed I who had made the transfer. Why did the bank not think of finding out (in a discreet manner) why all of a sudden so much money had moved out of my account, and if I was up to purchasing something and if the bank could help? Of course, later, during a visit to the Citibank local branch recently I found I wouldn’t have got a loan from them anyway since they don’t finance apartments built by no-name builders that are still under construction (which fits the bill of the property I’m purchasing). Nevertheless – the large money transferred out of my account could have been for buying a property that the bank could have financed. Missed opportunity there?
My understanding of the situation is that in several “analytics” offerings there is a disconnect between the tech and the business sides. Somewhere along the chain of implementation there is one hand-off where one party knows only the business aspects and the other knows only technology, and thus the two are unable to converse, leading to suboptimal decisions. One kind of value I offer (hint! hint!!) is that I understand both tech and business, and I can ensure a much smoother hand-off between the technical and business aspects, thus leading to superior solution design.


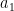 to
to 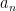 , then the quadratic variation of this series is measured as
, then the quadratic variation of this series is measured as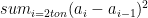
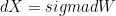
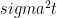 , which for t = 1 is
, which for t = 1 is 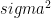 which is the variance of the process.
which is the variance of the process.


